So I got out my shiny new Neo4j 2.2.1, and started using Load CSV for getting the data in there. Essentially there were three steps:
- Importing the metadata about the riders and their twitter handles: importing the metadata
- Importing the actual tweets
- Processing the actual tweets
So let's go through this one by one. We will be using the following model to do so:
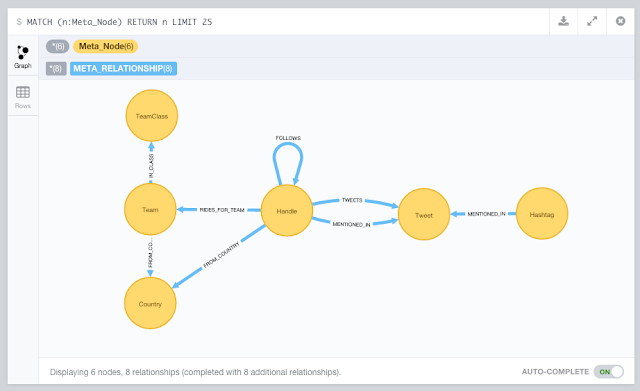
1. Importing the Cycling metadata into Neo4j
I wrote a couple of Cypher statements to import the data from CQ ranking:
//add some metadata //country info load csv with headers from "https://docs.google.com/a/neotechnology.com/spreadsheets/d/1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0/export?format=csv&id=1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0&gid=1390098748" as csv create (c:Country {code: csv.Country, name: csv.FullCountry, cq: toint(csv.CQ), rank: toint(csv.Rank), prevrank: toint(csv.Prev)}); //team info load csv with headers from"https://docs.google.com/a/neotechnology.com/spreadsheets/d/1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0/export?format=csv&id=1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0&gid=1244447866" as csv merge (tc:TeamClass {name: csv.Class}) with csv, tc match (c:Country {code: csv.Country}) merge (tc)<-[:IN_CLASS]-(t:Team {code: trim(csv.Code), name: trim(csv.Name), cq: toint(csv.CQ), rank: toint(csv.Rank), prevrank: toint(csv.Prev)})-[:FROM_COUNTRY]->(c); //twitter handle info using periodic commit 500load csv with headers from "https://docs.google.com/a/neotechnology.com/spreadsheets/d/1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0/export?format=csv&id=1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0&gid=0" as csv match (c:Country {code: trim(csv.Country)}) merge (h:Handle {name: trim(csv.Handle), realname: trim(csv.Name)})-[:FROM_COUNTRY]->(c); //rider info load csv with headers from "https://docs.google.com/a/neotechnology.com/spreadsheets/d/1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0/export?format=csv&id=1lLD2I_czto1iA1OjCMAZZxnYLAVsngBgjT5c0xuvpJ0&gid=1885142986" as csv match (h:Handle {realname: trim(csv.Name)}), (t:Team {code: trim(csv.Team)}) set h.Age=toint(csv.Age) set h.CQ=toint(csv.CQ) set h.UCIcode=csv.UCIcodeset h.rank=toint(csv.Rank) set h.prevrank=toint(csv.Prev) create (h)-[:RIDES_FOR_TEAM]->(t); //add the index on Handle create index on :Handle(name); create index on :Hashtag(name); create index on :Tweet(text); create index on :Handle(nodeRank); create constraint on (h:Handle) assert h.twitterId is unique;
As you can see, I also added some indexes. The entire script is also on Github.
The graph surrounding Tom Boonen now looked like this:

Once I had this, I could start adding the actually twitter info. That's next.
2. Importing the tweet data into Neo4j
As we saw previously, I had one CSV file for every day now. So how to iterate through this? Well, I did it manually, and create a version of this query for every day between April 1st and 30th.//get the handles from the csv file //this should not do anything - as the handles have already been loaded above using periodic commit 500load csv with headers from "file:<yourpath>/20150401.csv" as csv with csv where csv.Username<>[] merge (h:Handle {name: '@'+lower(csv.Username)}); //connect the tweets to the handles using periodic commit 500load csv with headers from "file:<your path>/20150401.csv" as csv with csv where csv.Username<>[] merge (h:Handle {name: '@'+lower(csv.Username)}) merge (t:Tweet {text: lower(csv.Tweet), id: toint(csv.TweetID), time: csv.TweetTime, isretweet: toint(csv.IsReTweet), favorite: toint(csv.Favorite), retweet: toint(csv.ReTweet), url: csv.`Twitter URL`})<-[:TWEETS]-(h);
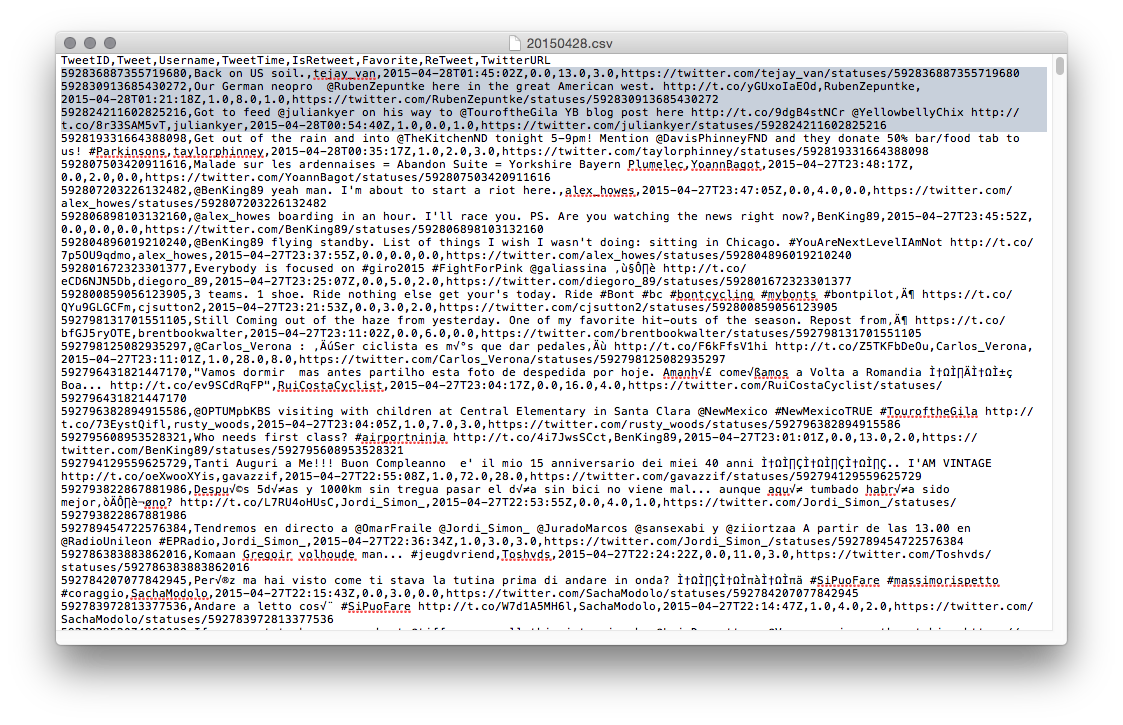
This file is also on Github, of course. I ran this query 30 times, replacing 20150401 with 20150402 etc etc... The result looked like this:

3. Processing the tweets: Extract the handles and the hashtags
I created two queries to do this - they are also on Github:And that's when we start to see the twitter network unfold: multiple riders tweeting and mentioning eachother://extract handles from tweet text and connect tweets to handles match (t:Tweet) WITH t,split(t.text," ") as words UNWIND words as handles with t,handles where left(handles,1)="@"with t, handles merge (h:Handle {name: lower(handles)}) merge (h)-[:MENTIONED_IN]->(t); //extract hashtags from tweet text and connect tweets to hashtags match (t:Tweet) WITH t,split(t.text," ") as words UNWIND words as hashtags with t,hashtags where left(hashtags,1)="#"with t, hashtags merge (h:Hashtag {name: upper(hashtags)}) merge (h)-[:MENTIONED_IN]->(t);

That's about it for this part 2. In the next section we will go into how we can enrich this dataset with more data about the connectedness between riders. Who is following who?
I hope you have liked this series so far. As always, feedback very welcome.
Cheers
Rik
No comments:
Post a Comment