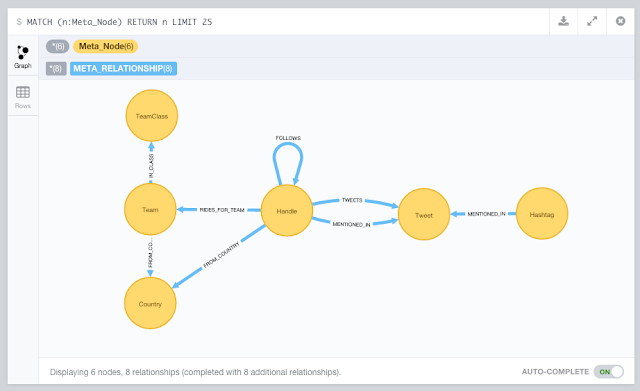
Here's the transcript of our conversation:
RVB: Hello everyone. My name is Rik, Rik Van Bruggen from Neo Technology, and we are recording another podcast again. Yippee. And today I'm on a Skype call with Johan, Johan Svensson, from Neo. Hi Johan.
JS: Hi, Rik. How are you?
RVB: I'm very well, and you? The sun is shining over here.
JS: I'm well, thanks.
RVB: [chuckles] So Johan--
JS: It's snowing in Malmø.
RVB: Okay. Johan, you've been one of the founders of Neo, right? But lots of people might not know you - would you mind introducing yourself a little bit, if you don't mind?
JS: Sure. As you said, I'm one of the founders of Neo4j and I'm currently the CTO of Neo Technology. I've been working with Neo basically since 2002, I would say, as it's been a long time now, and-- yeah.
RVB: That is a long time right? How did it start? How do you guys get started with Neo?
JS: Me, Emil, and Peter were working at this other company where we were building a content management system, and we had a lot of trouble pushing in the data we wanted to store into a relational database. I was mostly working at the-- what we call the-- I think we call it the kernel team, the core team or something, trying to get data in and out of the database. And it turned out that the things we tried to model wasn't a very good fit for a relational database, so that's where this new model came from. I was not initially part of all the-- it was mostly Peter and Emil who actually built-- Ali came up with this new model, and then I got started working with it when we tried to build the system that could handle this.
RVB: Was that really for performance reasons and stuff like that? Or what was the main reason for deciding, "We need something new here"?
JS: I think it was two-fold. One thing was performance and the other thing was modelling capabilities. The way we solved it in the system before we had Neo was basically store everything lazily and read everything up in memory on start-up. So my first project, when I started working at the company, was to actually optimise start-up time. That was 4 hours at the moment and we got it down to 30 minutes.
RVB: No way [chuckles].
JS: Yeah. But I mean it became clear that the tool we were using was not the right tool, and we had lots of hierarchies. Sometimes the hierarchy could have multiple parents which makes it a graph. We didn't think of it as a graph back then, but we spoke more about networks, and this year our case interlinked into each other in various way. So it became many dimensions and really, really hard to get into rows and columns.
RVB: How difficult was it for you to create the minimal product, so to speak? Was it months? Was it years? How much time did you spend on the first versions?
JS: We started and first we did just a few proof of concept versions that I was not part of, in using EJBs, and what we got from that was basically that the model works really, really well, it solves our modelling problems, but probably didn't solve our performance problems. So then we tried to do a new version more directly on top of Postgres, and that still didn't work out for us. And then I've been experimenting on my own, because Java had just released Java Nio, a new way of doing IOs. So I've been experimenting some with our own native-- like building a native solution for storing graphs, and it turned out that that one performed much, much better.
RVB: That was when you started to really try to have your own file system format and all those types of things, is that what I'm hearing?
JS: Exactly, yes. We started building that, I believe in-- was it mid 2002 or maybe early 2002, I can't remember, and then we put the first system in production in 2003.
RVB: And when did it start taking the shape that Neo4j has today, like a database, like a full-on database? When would you say was the first version of Neo as a database?
JS: Well, you could argue that the first version that we put in production was a database. I mean, it had all the requirements, but on the other hand it was very early and being built quite fast, so-- it always takes many years before you have a stable database. I actually believe-- what's his name? Curt Monash says that it takes at least five years to build a database. We had lots of problems with it in the beginning, of course, but it was only hosting our own system so we could easily handle that. Then we saw that this is absolutely something-- technology that we could use in other projects and we could even use this technology as creating a product around it. But there was no real way of doing back then because object-oriented databases had just failed, so there was no one who was challenging the relational databases back then, so we didn't do that. But then Dynamo came around and things started happening in 2006. That's when we actually spun out the IP in a separate company, and started Neo Technology.
RVB: That's when we started surfing the NOSQL wave, right [chuckles]?
JS: Yes, well that came a few years later, I guess, before someone put a name on that. But, yeah.
RVB: Essentially, yeah. So you mentioned already that it was around performance and modelling, those were the two things. Are there any other things that you think are super great about Neo graph databases today, or why you think that people should be looking at it right now?
JS: I think it enables people to solve the problems that they haven't been able to solve before. Basically, any field if you look at it today, that stores data in an old-fashioned way, they're not making use of their data. The thing that comes to mind always when I think about this, is actually healthcare. I think that we could do a lot of things in the areas to help the world or help doctors make better diagnosis, and so on. There are so many things we can do. The data is already there, we're just not making sense of it.
RVB: We're not making the connections.
JS: Exactly. So if we start doing that, we're going to have a much better society, I would say.
RVB: Yeah, absolutely. So that also sort of brings me to my last question - where is this going? Where do you see Neo as a technology going, but also where do you see the industry going? Any interesting comments about that?
JS: Yeah. I wouldn't be doing this unless I was convinced that we have something big. I actually think that the majority of data will soon be stored in graph databases. And that soon, that maybe two, three, four, five, ten years, I don't know but I think that's where we are going. And when it comes to technology, I have a lot of things [laughter] on my mind. I don't know how technical you want to get there, but--
RVB: Well, just the big things, right.
JS: We just released 2.2 which is a very nice improvement. I think it's our most solid release so far. It basically lays the foundation for us to be doing a lot of work that we have wanted to do for a long time but have not been able to do because of old legacy things. Some of the code that I wrote back in 2003 is still there, but it's getting less and less and less. Right now, I would say that we have come to a point where I think we can accelerate a lot of the things we want to build. 2.3 is going to be something that improves both stability and it's going to improve performance over 2.2. Then we have three overlays coming that we'll introduce some great things, specifically around how to interact with the product but also in continue the internal work that you don't see so much of a user-- as a user, like the product surface doesn't change that much but, still, it's going to be a lot of changes and much of this is actually driven from our hardware levels. If you look at how a computer looks today and how it will look tomorrow, that's very different from what it looked liked 10 years ago or 20, 30 years ago, when many of the other databases were designed and built. So, I think we see great things coming.
RVB: Fantastic. Well, Johan, thank you so much for coming on the podcast. I know there are so many things we could talk about, but we want to keep these fairly short. I really appreciate you making the effort to come online. Thank you so much for doing that.
JS: You're welcome. Thanks.
RVB: All right, have a good one. Bye.
JS: Bye.
Subscribing to the podcast is easy: just add the rss feed or add us in iTunes! Hope you'll enjoy it!
All the best
Rik