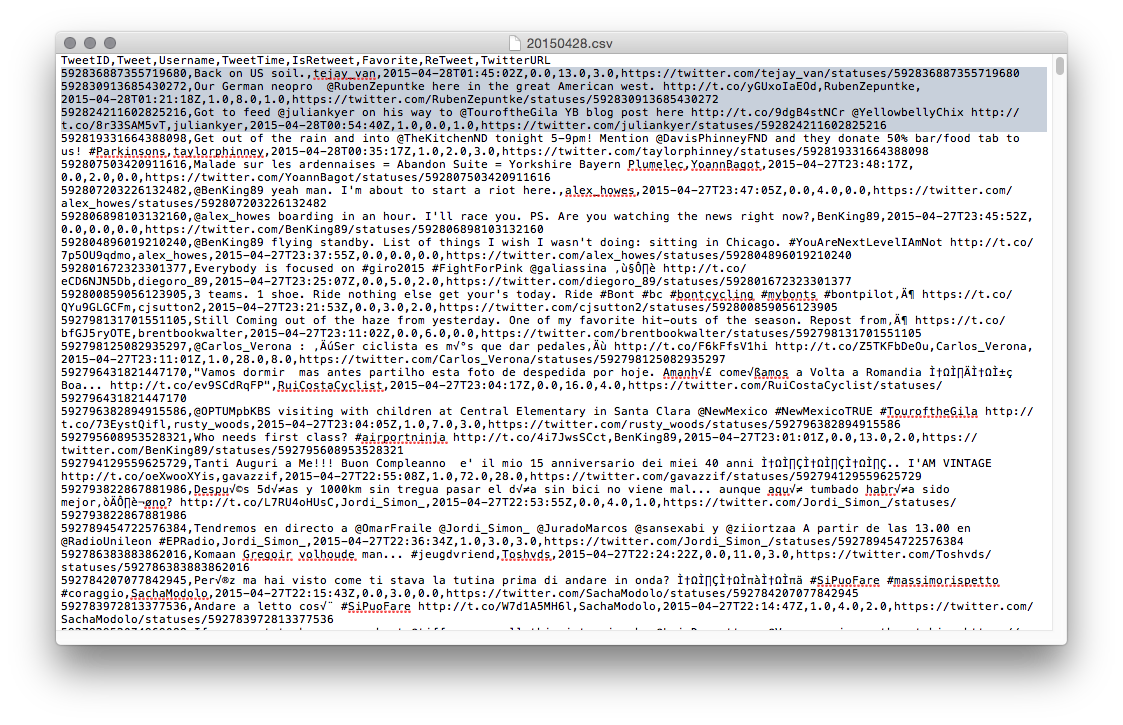
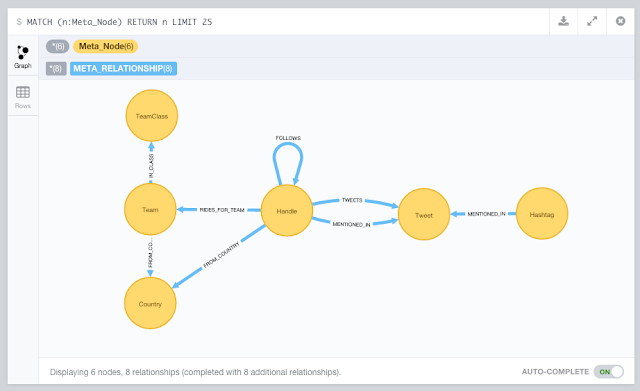
One of these modules is the "NodeRank" module. This implements the famous "PageRank" algorithm that made Google what it is today.

- drop the runtimes in the Neo4j ./plugins directory
- activate the runtimes in the Neo4j.properties file that you find in your Neo4j ./conf directory.
Here's what I added to my server (also available on github):
//Add this to the <your neo4j directory>/conf/neo4j.properties after adding //graphaware-noderank-2.2.1.30.2.jar and //graphaware-server-enterprise-all-2.2.1.30.jar //to <your neo4j directory>/plugins directory com.graphaware.runtime.enabled=true #NR becomes the module ID: com.graphaware.module.NR.1=com.graphaware.module.noderank.NodeRankModuleBootstrapper #optional number of top ranked nodes to remember, the default is 10 com.graphaware.module.NR.maxTopRankNodes=50 #optional damping factor, which is a number p such that a random node will be selected at any step of the algorithm #with the probability 1-p (as opposed to following a random relationship). The default is 0.85 com.graphaware.module.NR.dampingFactor=0.85 #optional key of the property that gets written to the ranked nodes, default is "nodeRank" com.graphaware.module.NR.propertyKey=nodeRank #optionally specify nodes to rank using an expression-based node inclusion policy, default is all business (i.e. non-framework-internal) nodes com.graphaware.module.NR.node=hasLabel('Handle') #optionally specify relationships to follow using an expression-based relationship inclusion policy, default is all business (i.e. non-framework-internal) relationships com.graphaware.module.NR.relationship=isType('FOLLOWS') #NR becomes the module ID: com.graphaware.module.TR.2=com.graphaware.module.noderank.NodeRankModuleBootstrapper #optional number of top ranked nodes to remember, the default is 10 com.graphaware.module.TR.maxTopRankNodes=50 #optional damping factor, which is a number p such that a random node will be selected at any step of the algorithm #with the probability 1-p (as opposed to following a random relationship). The default is 0.85 com.graphaware.module.TR.dampingFactor=0.85 #optional key of the property that gets written to the ranked nodes, default is "nodeRank" com.graphaware.module.TR.propertyKey=topicRank #optionally specify nodes to rank using an expression-based node inclusion policy, default is all business (i.e. non-framework-internal) nodes com.graphaware.module.TR.node=hasLabel('Hashtag') #optionally specify relationships to follow using an expression-based relationship inclusion policy, default is all business (i.e. non-framework-internal) relationships com.graphaware.module.TR.relationship=isType('MENTIONED_IN')
As you can see from the above, I have two instances of the NodeRank module active.
- The first attempts to get a feel for the importance of "Nodes" (in this case, the nodes with label "Handle") by calculating the nodeRank along the "FOLLOWS" relationships. After just half an hour of "ranking" we get a pretty good feel:

This seems to be confirming - in my humble opinion - some of the more successful riders in April, for sure. But also confirms that the "big names" (Contador, Froome, Cancellara) are attracting their share of Twitter activity no matter what. - The second does the same for the "Topics" (in this case, the nodes with the label "Hashtag") along the the "MENTIONED_IN" relationships.

The classic races are clearly "top of mind" in the Twitterverse! But upon investigation I have also found that there are a lot of confusing #hashtags out there that make it difficult to understand the really important ones. Would love to investigate a bit more there.


Like I said before, the GraphAware framework is really interesting. It gives you the opportunity to make stuff that you could also do in Cypher more easily, faster, and more consistently. I really liked my experience with it.
Hope this was useful for you - as always feedback is very very welcome.
Cheers
Rik