Why your AI project is actually failing–and how to fix the foundation
You’ve probably seen the headline by now: “95% of generative AI pilots fail to deliver measurable ROI.” It’s been included in just about every article and presentation on the AI topic recently - and it’s most definitely sparked a familiar fear – that we’re living through another overhyped AI bubble.
But that number, taken at face value, misses the real story. Because what’s failing isn’t AI. It’s how organizations are trying to adopt it. Once you look past the headline and into what the research actually measured, a different picture emerges—one that’s far more practical, and far more fixable.
Here is a critical breakdown of what the research really showed, what it did not show, and the non-negotiable architectural mandate required to transition your projects from the volatile 95% bracket into the successful 5%.
1. What the research really showed: A failure of integration, not intelligence
The MIT Media Lab’s Project NANDA (who advocate for decentralised web of AI agents (see their projected evolution in the chart below), and as such are somewhat biased towards the current state of AI) report defined “failure” precisely: the inability of the AI pilot to transition beyond the proof-of-concept stage and achieve rapid revenue acceleration or a substantial, measurable return on investment (ROI).

In other words, these weren’t models that didn’t work. They worked just fine in controlled environments. However, they failed when they hit the real world.
The researchers describe this as a “learning gap” – the moment when an AI system leaves the lab and runs into fragmented data, unclear ownership, and workflows that were never designed for intelligence to plug into them.
So the takeaway isn’t “AI doesn’t work.”
It’s “we’re dropping AI into environments that aren’t ready for it.”
Why AI projects stumble: it’s usually not the tech
When AI initiatives stall, the real roadblocks are usually internal – specifically how we try to fit the technology into our existing organization and where we decide to spend the money.
First, let's talk about the Integration problem.
Dropping a powerful but generic tool like a Large Language Model (LLM) into a complex company is like trying to use a foreign body in a human system – it just doesn't mesh. For these tools to actually work, we need more than just the software; we need to break down the departmental silos, establish clear governance, and define exactly how the new AI connects with our current systems. Without that framework, the tech is essentially an outsider that can't access the necessary context to be effective.
The second big issue is the strategic misalignment, which I call the "Visibility Trap”, which also indicates a strategic mismatch in where money gets allocated.
A large share of AI budgets flows toward visible functions like Sales and Marketing. But MIT’s own data shows the highest measurable ROI comes from back-office automation – reducing repetitive internal work and operational drag The conclusion is clear and simple: we often fund what looks impressive instead of what actually compounds value.
Bottom line: the AI isn’t failing. The organization is failing to prepare the ground it’s meant to operate on.
2. The core obstacle: the data readiness crisis
If strategic failure kills ROI in the pilot phase, data fragmentation kills the rollout in the production phase. Gartner data supports this operational challenge, showing that only 48% of AI projects successfully transition into production.6
The single biggest blocker to rolling out AI is the state of enterprise data, which we can dissect into three components:
The unstructured data problem:
Most enterprise data – emails, tickets, documents, logs – is unstructured. It lacks consistent context and labeling, making it unusable for reliable, auditable AI unless it’s heavily cleaned first.
The fragmentation trap:
Customer context is spread across CRMs, ticketing systems, engineering tools, and ERPs. Stitching this together with brittle API calls doesn’t scale. It slows systems down and introduces failure points.
The trust gap:
When leaders can’t trace answers back to source data –or predict how the system will behave – they won’t rely on it for real decisions. That’s when projects quietly get shelved.
Without good data, no good decisions. That eternal truth is why so many promising projects end up getting abandoned - the lack of good data makes it so that they are simply set up to fail.
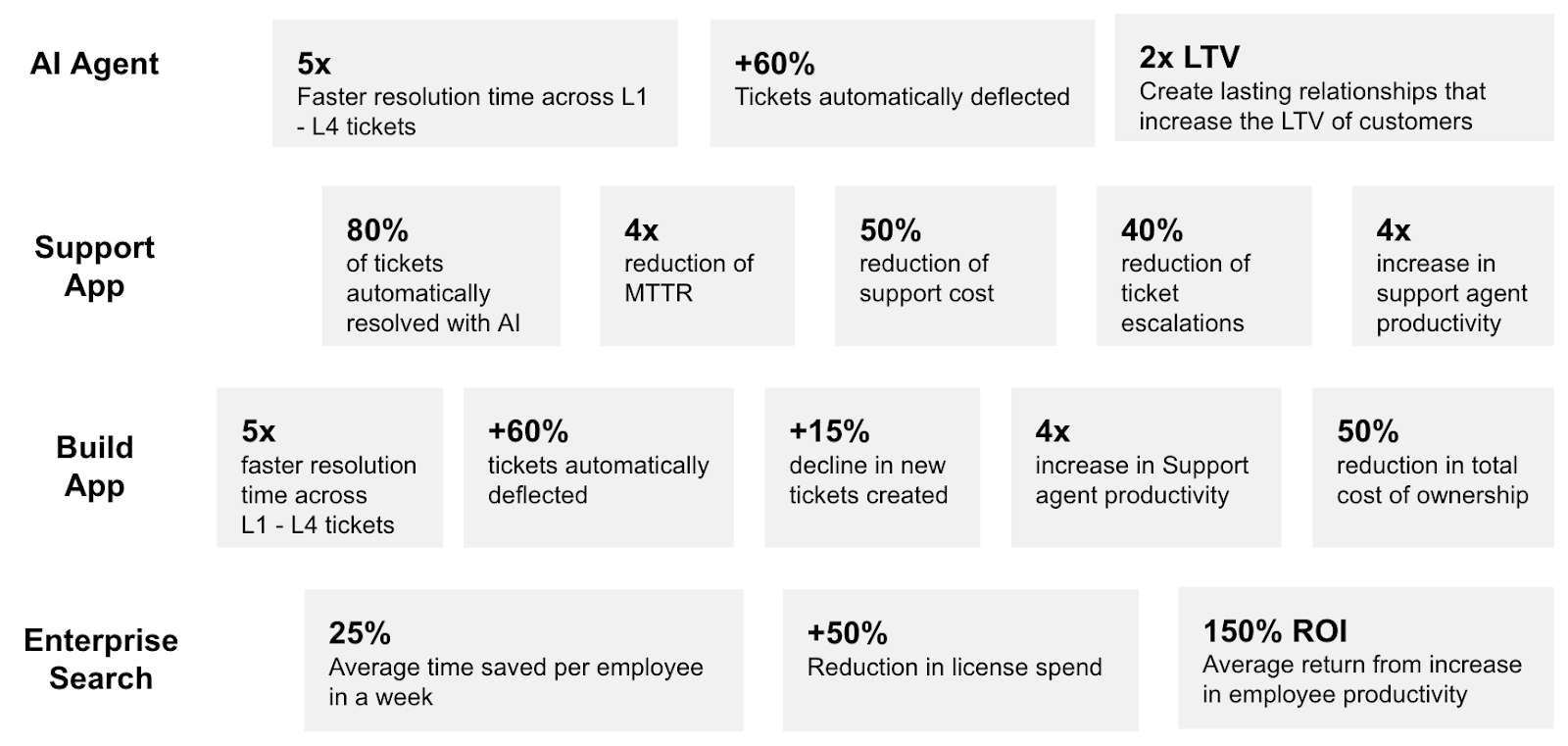
What do the successful 5% do differently?
To succeed where 95% of companies stall, you must pivot from model-centric optimization to a data-centric architectural foundation.7 This requires securing three critical capabilities: Context, Trust, and Action.
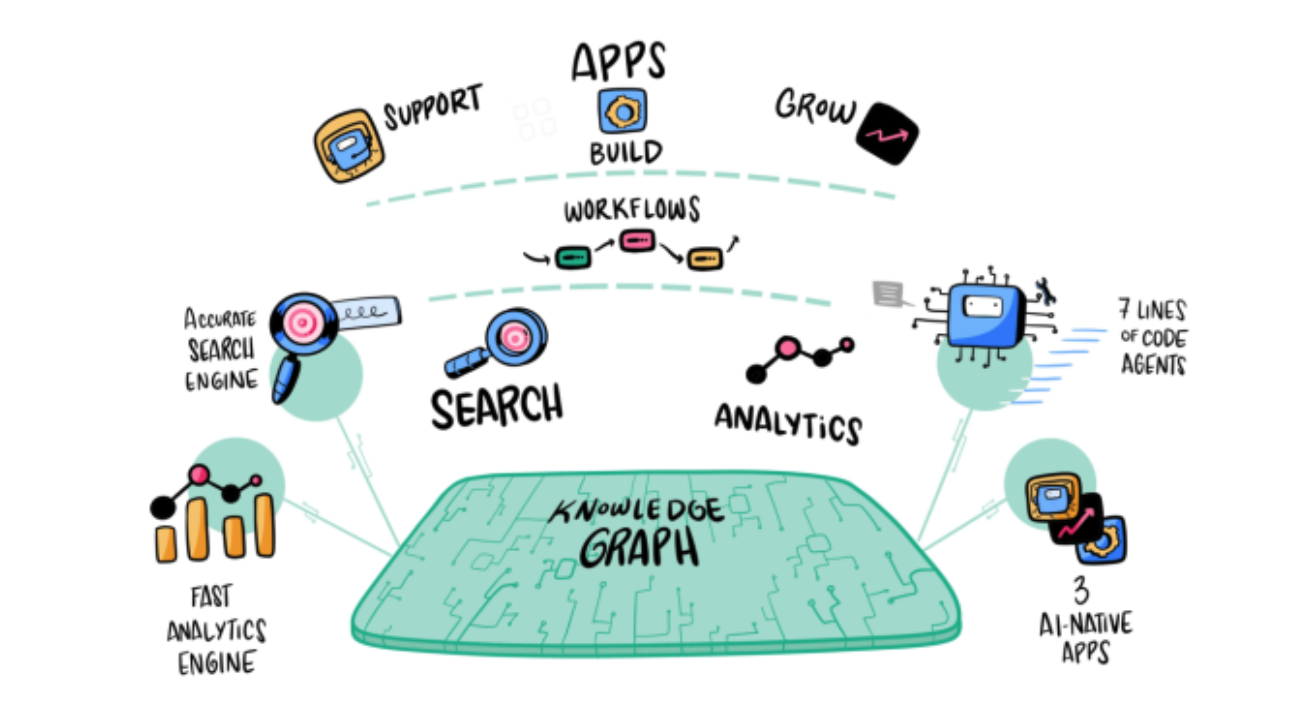
This is where a platform like Computer by DevRev fundamentally re-architects the problem, ensuring your AI initiatives are grounded in a ready-made, unified data layer.
How DevRev addresses the foundation problem
Let’s walk through the three things that DevRev does, as part of our yearlong effort to architect Computer from the ground up for this purpose, very differently.
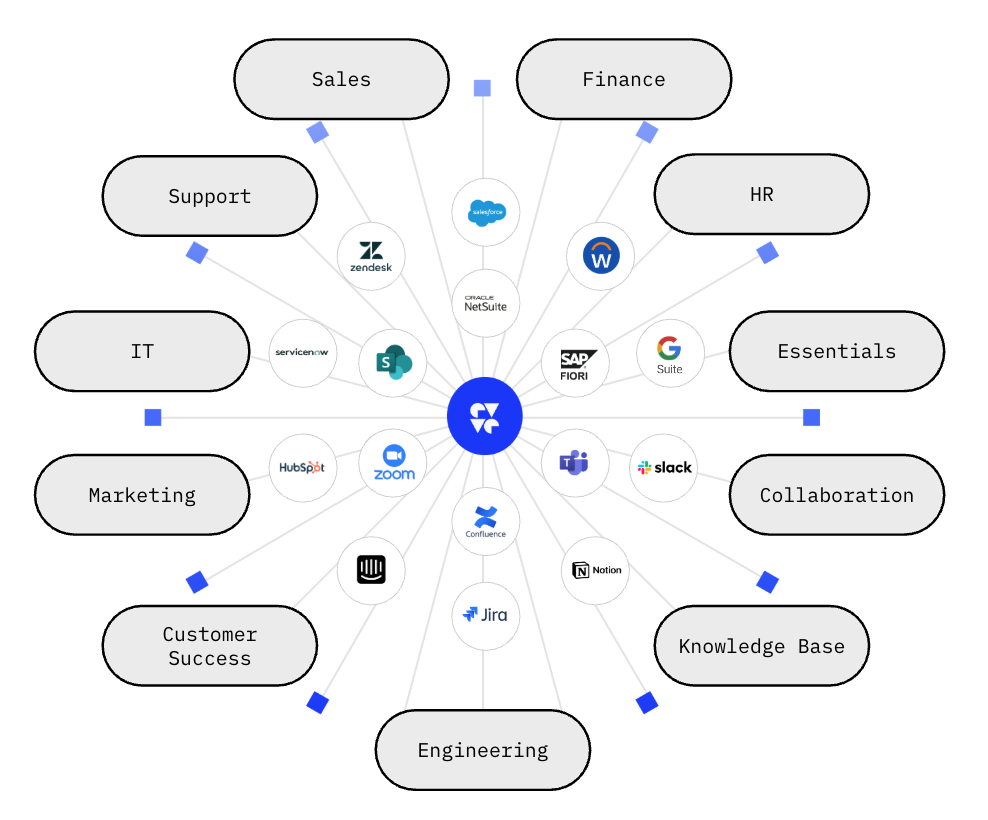
1. Context: fixing fragmentation with a unified data layer
DevRev replaces fragile data federation with physical consolidation. Using bi-directional sync, data from CRM, support, engineering, and other systems is continuously pulled into a single store. That data is then structured as a relationship-rich knowledge graph – linking customers to tickets, tickets to code, and code to documentation.
This turns scattered, unstructured data into something AI can actually reason over.
2. Trust: grounding AI in auditable queries
To address governance and hallucination concerns, DevRev grounds conversational AI in an auditable layer. Natural-language questions are translated into standard SQL queries against the unified data layer. That means answers are:
This is what makes enterprise-grade trust possible.
3. Action: closing the learning gap
Insight alone doesn’t deliver ROI. Because DevRev is a system of record, its AI agents are write-enabled. They don’t just answer questions – they can update tickets, log bugs, assign ownership, and execute changes inside real workflows. That’s how the “learning gap” closes: insight turns into action, and action turns into measurable operational impact.
The real lesson behind the 95%
The 95% failure rate isn’t a warning about AI, really. It’s a warning about treating AI like a plug-in instead of a system. GenAI success depends on foundations – context your AI can understand, trust your leaders can audit, and actions that move work forward automatically. When those are in place, AI stops being experimental – and starts compounding value.
If you want to dig deeper into DevRev, Computer, or any of the ideas here, I’m happy to continue the conversation.
All the best
Rik