And then Facebook Graph Search came along, along with it’s many crazy search examples - and it sort of hit me: we need to illustrate this with *queries*. Queries that you would not - or only with a substantial amount of effort - be able to do in traditional database system - and that are trivial in a graph.
This is what I will be trying to do in this blog post, using an imaginary dataset that was inspired by the Telecommunications industry. You can download the dataset here, but really it is very simple: a number of “general” data elements (countries, languages, cities), a number of “customer” data elements (person, company) and a number of more telecom-related data elements (operators - I actually have the full list of all mobile operators in the countries in the dataset coming from here and here, phones and conference call service providers).
So to start of with: what would this data set look like in a relational model?

What is immediately clear is that there is *so* much overhead in the model. In order to query anything meaningful from this normalised rdbms, you *need* to implement these things called “join tables”. And really: these things stink. It is just an example of what a poor match the relational model is to the real world - and the complexity it introduces when you start using it.
Compare this to the elegance of the graph model:

It is such a good match to reality - it is just great. But the beauty is not just in the model - it’s in what you do with the model, in the queries.
So let’s how we could ask some very interesting, Facebook style, queries of this model:
- Find person in London who speaks more than one language and who owns an iPhone5
- Find a city where someone from Neo Technology lives who speaks English and has Three as his operator
- Find a city where someone from Neo Technology lives who speaks English and has Three as his operator in the city that he lives in
- Find a person, not living in the Germany, who roams to more than 2 countries and who emails peoplewho live in London
- Find a person who roams to more than 2 countries and who lives in the USA and uses aConferenceCallService there
These are all very realistic queries that could serve real business purposes (pattern recognition, recommendation engines, fraud detection, new product suggestions, etc), and that would be terribly ugly to implement in a traditional system, and surprisingly elegant on a graph. To do that, we would use our favourite graph query language, Cypher, to describe our patterns and get the data out.
So let’s explore a couple of examples with some real world queries.
In the example below you can see that we are using three index lookups (depicted in green, and I even added a nice little parachute symbol to illustrate what we are doing here) to “parachute” or land into the network, and start walking the graph from there.

The query above is to look for a city where someone from Neo Technology lives that speaks English and has Three as his operator in the city that he lives in.
// These are the three parachutes, landing by doing an index lookup for nodes using the node_auto_index of Neo4j.
START
neo=node:node_auto_index(name="Neo Technology"),english=node:node_auto_index(name="English"),
three=node:node_auto_index(name="3")
// Here we describe the pattern that we are looking for. From the three starting points, we are looking for a city that has very specific, directed relationships that need to match this pattern.
MATCH
(person)-[:LIVES_IN]->(city)-[:LOCATED_IN]->(country),
(person)-[:HAS_AS_HOME_OPERATOR]->(three)-[:OPERATES_IN]->(country),
(person)-[:SPEAKS]->(english),
(person)-[:WORKS_FOR]->(neo)
// We return the city’s name and the person’s name as a result set from this query.
RETURN city.name, person.name
// and order them by the name of the city
ORDER BY city.name;
And here’s another example:
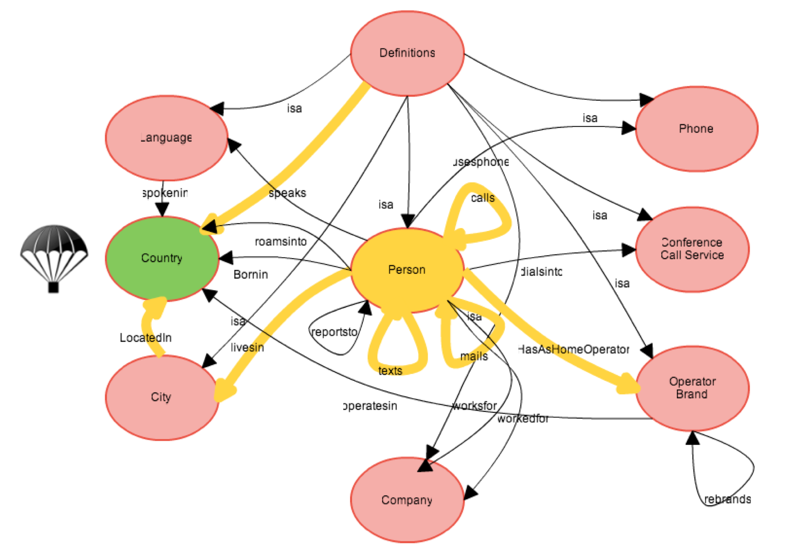
Here are are looking for two people in the same countries but on different home operators that call, mail or text each other.
// Here we use just one index lookup to find a “country” and then we start looking for the pattern.
START
country=node:node_auto_index(name="Country")
// The pattern in this case is quite a complex one, we quite a few hops on the different relationship types.
MATCH
(samecountry)-[:IS_A]->(country),
(person)-[:LIVES_IN]-()-[:LOCATED_IN]-(samecountry),
(otherperson)-[:LIVES_IN]-()-[:LOCATED_IN]-(samecountry),
(person)-[:HAS_AS_HOME_OPERATOR]->(operator),
(otherperson)-[:HAS_AS_HOME_OPERATOR]->(otheroperator)
// Here we limit the results to a specific condition that has to be applied.
WHERE
(otherperson)-[:CALLS|TEXTS|EMAILS]-(person)
AND operator <> otheroperator
// And here we return the distinct set of name of the person and the countries’ name.
RETURN DISTINCT person.name, samecountry.name;
I am hoping that you can see that these kinds of queries, which directly address the nodes and relationships rather than going through endless join-tables, is a much cleaner way to pull this kind of data from the database.
The nice thing about this way of querying is that in principle, its performance is extremely scalable and constant: we will not suffer the typical performance degradation that relational databases suffer when doing lots of joins over very long tables. The reason for this is simple: because we only use the indexes to find the starting points, and because the other “joins” will be done implicitly by following the relationships from node to node, we can actually know that performance will remain constant as the dataset grows. Finding the starting point may slow down (a bit) as the index grows, but exploring the network will typically not - as we know that not everything will be connected to everything, and the things unconnected to the starting nodes will simply “not exist” from the perspective of the running query.
Obviously there a lot more things to say about graph queries, but with these simple examples above, I hope to have given you a nice introduction as to where exactly the power of graph traversals is - and it’s in these complex, join-intensive queries.
Yours sincerely,
Rik Van Bruggen.
