I am not a programmer
Probably the single most obstacle to myself getting involved with Neo4j as a user, was that I don’t know how to program. I mean, at University I did *some* programming, but I think the world should be thankful for the fact that none of my code ever made it into production. Seriously. I suck at programming. Probably because I don’t really enjoy DOING it. I like talking about it, I love watching OTHER people do it (!), but I just don’t have the talent or the inclination to really do development. Sorry.
But let’s face it, Neo4j in 2012 was really very much a *developer tool*. It was not, by any means, something that you could hand of to a business user, let alone a database administrator, to really use in production. And I am neither of those. I am a sales person, and I love my job with a passion.
So how could I ever get stuck in with a development centric open source project like Neo4j? Well, I believe it’s really simple.
- Ask great people for help. Don’t be afraid or ashamed to say that you don’t know something, and ask the people that do know for assistance. There are some great people in our community, and even more so at Neo Technology. As one of my colleagues put it: “NeoTech is so great, because there are no assholes here…”. Haha. There’s a lot of truth in that: my colleagues are great, and they help me whenever they can. I would love have been able to write this blog, write the book, speak at conferences, without their support.
- Failure is good. I think that’s probably the biggest thing that I learned along the way - and that I see lots of people NOT doing - is that they hold back, for fear of failure. They are standing on the sea shore, and are afraid to jump in - in spite of the fact that there are swimming teachers, rescue vests, lots of other swimmers and even the rock-star shark fighters available if something would go wrong. People just don’t try. And when they fail, they don’t ask for help (see above) and retry.

Learning Neo4j
Of course, a Graph Database like Neo4j is new, or at least newish technology. So it is bound to be a bit different, and rough around the edges. If you can’t live with that, times are going to get rough. So what were the key new things that I had to get my mind around? Let’s go through the top three.1. Learning how to Model
Modelling in a graph database is different, especially if you come from a relational background. Relational databases have many good things about them, but one of the inherent limitations to that model is that it’s actually quite “anti-relational”. What I mean is: every time you you introduce a new connection between two entities, you pay the price of having to join these two entities together at query time. Even worse in n-to-m connections, as that introduces the unnecessarily complex concept of a “join table”. So, so annoying. But the thing is, that we are used to thinking in that way - that’s how we were educated and trained, that’s how we practiced our profession for decades, so … we almost can’t help it but doing it that way.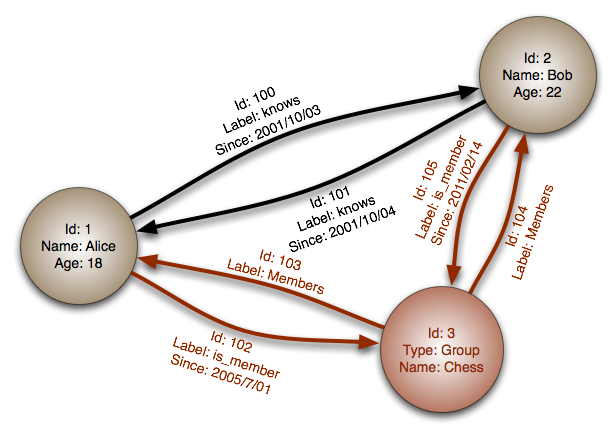
The fundamental difference in a graph model, I believe, is that introducing relationships/connections is cheap - and that we should leverage that. We can normalise further, we can introduce new concepts in the graph that we otherwise forget, we can build redundancy into our data model, and so on and so on. I won’t go into the details of Graph Database modelling here, but suffice to say that it’s different, and that I had to go through a learning curve that I would imagine would required for most people. It pays to model - and you should take your time to learn it, or ask for assistance to see if it makes good sense or not.
2. Learning Import
Once you have a model, you probably want to import some data into it. That, for me, was probably the biggest hurdle that I had to get over in order to learn Neo4j. I remember messing about with Gephi and Talend trying to generate a Neo4j database just to avoid having to use the import tools that were available 2.5 years ago, and asking myself why oh why is that so difficult. Surely there must be better ways to do that.I meanwhile believe that Importing data into a Graph Database is *always* going to be a bit tricky (for the simple reason that you have to write data AND structure at the same time), but that there are specific tools around for specific import use cases. Now, luckily, these tools have moved on considerably, and I think if you look at my last “summary” of the state of Neo4j import tools, it has gotten a LOT better. My rule of thumb these days is that
- for anything smaller than a couple of thousand nodes/relationships, I will use cypher statements (often generated with a spreadsheet, indeed) to import data.
- for anything up to a couple hundred thousand, and lower millions of nodes and relationships, I will usually resort to using LoadCSV, the native ETL capability of Cypher.
- for anything that requires higher millions or billions of nodes and relationships to be imported, I will use the offline, batch-oriented tools.
3. Learning Cypher
Last but not least, I really feel that learning Cypher, the declarative query language of Neo4j, is totally worth the while. It may seem counterintuitive at first: why do I need to learn yet-another-query-language to deal with this Neo4j thing - until you start using it. Things that are terribly hard in SQL, become trivially easy in Cypher. Queries of a 1000 lines or more in SQL, fit on half a page in Cypher. It’s just so, so powerful. And I have found that the learning curve - even for a non-developer like myself - is very, very doable. I would not call myself a Cypher expert, but I definitely feel more than confident enough today to handle quite sophisticated queries. And again: if I get stuck, I nowadays have books about Cypher, websites like Wes’, and friendly people everywhere to help me. Cypher - in my opinion - is the way to go, and Neo4j is only going to make it better with time.That’s about it, in terms of my big lessons learnt on this wonderful Graph Journey. So let’s wrap it up.
Having fun while learning
I think the final thing here that I would like to add is that Learning Neo4j, even though a bit painful sometimes, has been a tremendously FUN experience, above all. Why otherwise would I come up with Graph Karaoke?I believe that to be really, really important. Learning should be fun. So the more you can play with interesting datasets, the more you have the opportunity to share and discuss about that with your friends and colleagues, the more fun you will have and the more you will enjoy getting stuck in and learn some more. So set yourself up that way. Don’t be a lonely document out there - but connect with others and leverage the graph. I for one, am not regretting it for a second.
Hope this story was useful. Comments and questions always more than welcome.
Cheers
Rik