One of the things that I have always found extremely fascinating about Neo4j, and **extremely** annoying about relational database systems, is the way both scale.
In a relational system, you are often confronted with the fact that queries work fine on your development environment, but then when you go into production and run the same query on a production dataset, it all blows up. As one customer recently put it to me, "the fecal matter would hit the air rotating device". Indeed.
In a graph database, that typically would not happen. Because of the fact that we use index-free adjacency we can pretty much know beforehand that a query that runs fine on a small dataset, will still run fine on a large dataset. The query is local, does not even see the entire graph as it traverses the dataset - it will just traverse that part of the graph that is known to it and accessible from the starting point of the graph query.
Recently, I found a great way to prove that point. Let me take you through that experiment.
Adding a small dataset
I had the opportunity to play with a small dataset of meteorological data recently. It's not very fancy - just a small dataset with a fairly simple model:

The dataset was small: only containing 148 nodes:
as we will be using the index to find the starting point of our queries. If I then ran a query that would look for the EQUIPMENT_TYPE of certain OBSERVATIONs (which is a fairly extensive traversal in our small model, this would look like this:
match
(eqt:EQUIPMENT_TYPE)<-[:IS_OF_TYPE]-(eq:EQUIPMENT)-[:LOCATED_AT]->(ol:OBSERVATION_LOCATION)<-[:OBSERVED_AT_LOCATION]-(o:OBSERVATION {id:1001})return eqt.name, ol.name, o.id;
On the small dataset that query runs instantaneously: 64 milliseconds.

Then, however, we would like to see if the graph local scalability claim is really true.
Adding half a million observations
What I decided to do was to run a small cypher query that would add a large number of observations to the dataset.
using periodic commit 10000
match (o:OBSERVATION)-[r:IS_OF_TYPE]->(ot:OBSERVATION_TYPE),
(o)-[s:OBSERVED_AT_LOCATION]->(ol:OBSERVATION_LOCATION)
with range(1,10000) as RANGE,o,r,ot,s,ol
foreach (ran in RANGE | create (ot)<-[:IS_OF_TYPE]-(newobservation:OBSERVATION:DEMO {id: ran+1000000, date: round(rand()*100)+41000 , amount: round(rand())+1 })-[:OBSERVED_AT_LOCATION]->(ol) );

Then, we could run the same query as above, but for a different observation, on the new, larger dataset.
Query times at scale: nearly identical
If I now run the same query as above on the larger dataset - but for a different observation - then I am happy to report that the query times are nearly identical:
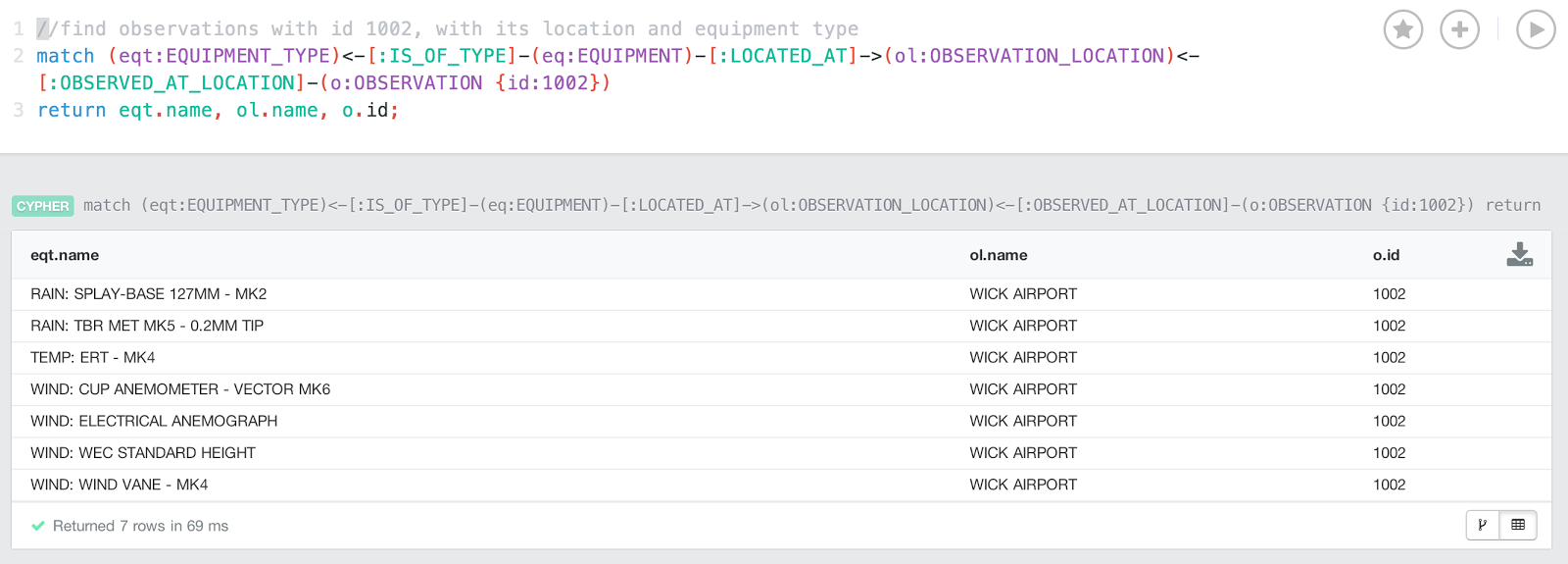
Case in point: the new query runs for about 69 milliseconds.
I truly believe that this is one of the fantastic characteristics of graph databases. Query times typically are not dependant of dataset size - rather dependent of the part of the graph that is traversed, essentially dependant on the result set size.
Hope this was a useful explanation of graph local queries and graph database scalability. I certainly enjoyed it - hope you did too.
Cheers
Rik
Hi Rik,
ReplyDeleteVery nice article! Would you please share the configuration settings for your neo4j server?
The key thing was that I had about 4G of heap allocated... You can allocate that in neo4j-server.conf... Nothing special other than that!
DeleteHi Rik,
ReplyDeleteThanks for posting this insightful article! I'm curious if you have done any performance testing with nodes that have many relationships connected to them. For example, one OBSERVATION having thousands of OBSERVED_AT_LOCATION and LOCATED_AT relationships. I speculate for a large amount of relationships, matching a specific type of relationship would take longer as the match operation is O(n).
Thanks,
Andrew
Hi Andrew
Deletedefintely, having dense nodes is an "issue" to think about. But: with Neo4j 2.1 it has definitely become less of an issue, as we have done some technical rework/optimisation on how to deal with that. On hitting such a node during the traversal, the performance may indeed go down a bit, but not as much as it used to... And in any case, you can always "model out" the dense nodes if that would be necessary - it's pretty easy to do usually.
Hope that helps. Ping me if you need anything else.
Rik
Thanks Rik, that does help. I found some more information regarding dense nodes on the forum:
Deletehttps://groups.google.com/forum/#!msg/neo4j/g63fTmPM4GE/43y_QhDJSaoJ
It reiterates what you mentioned about modeling out and Neo4J 2.1.
Cheers,
Andrew
Hi Rik,
ReplyDeleteNice post. I'm a newbie to Neo4j, so I'm just wondering if your query is correct. It seems to me that it should also include the following clause in the match: (eq)->[:USED_FOR]->(ot:OBSERVATION_TYPE)<-[:IS_OF_TYPE]<-(o)
Am I off base? If not, I'd like to see your performance figures with the addition of this clause. Although I suspect there may be little difference from your original figures, I think it might be interesting to see how the slightly more complex query would scale, perhaps making your point even a bit stronger.
Thanks,
Chuck
Hey Chuck,
Deletegood question. I decided to take some time to check this - hence the slow response. But here we are: http://blog.bruggen.com/2014/06/graph-local-queries-revisited.html has the new test explained for you - and YES, it's still confirming the awesomeness of graph local queries :)
Hth
Rik