Recently I was talking to one of our clients who was looking to put in place a knowledge graph for their organisation. They were specifically interested in better monitoring and making sense of the industry news for their organisation. There's a ton of solutions to this problem, and some of them seem like a really simple and out of the box toolset that you could just implement by giving them your credit card details - off the shelf stuff. No doubt, that could be an interesting approach, but I wanted to demonstrate to them that it could be really much more interesting to build something - on top of Neo4j. I figured that it really could not be too hard to create something meaningful and interesting - and whipped out my cypher skills and started cracking to see what I could do. Let me take you through that.
The idea and setup
I wanted to find an easy way to aggregate data from a particular company or topic, and import that into Neo4j. Sounds easy enough, and there are actually a ton of commercial providers out there that can help with that. I ended up looking at Eventregistry.org, a very simple tool - that includes some out of the box graphyness, actually - that allows me to search for news articles and events on a particular topic.
So I went ahead and created a search phrase for specific article topics (in this case "Database", "NoSQL", and "Neo4j") on the Eventregistry site, and got a huge number of articles (46k!) back.


Once you make the sheet available on the internet, you can then also download this sheet as a CSV by accessing a specific URL: https://docs.google.com/spreadsheets/d/1G1Dfh-6Ue2nK17CGoEMiNfIjhYO05h9EJaRX9sDUxJI/gviz/tq?tqx=out:csv&sheet=news. That way we don't have to put anything on our local file system.
Importing the news articles
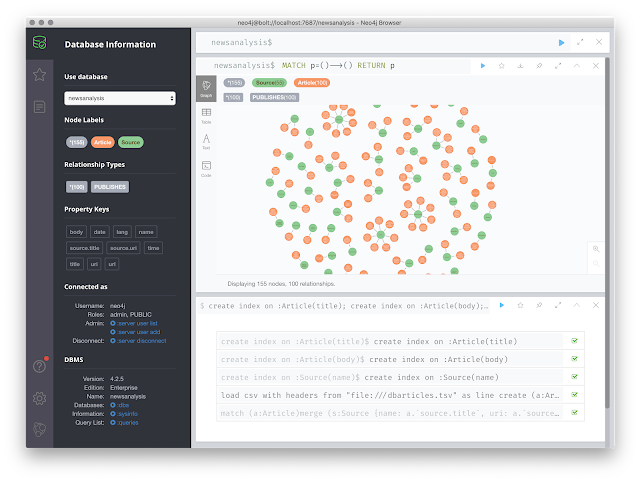
Once we have the articles in this format, we can really easily import them. All we need to do is prepare our graph by setting up some indexes:
create index on :Article(body);
create index on :Source(name);
and then use Cypher to load the data from the from the CSV on the URL above:
create (a:Article)
set a = line;
match (a:Article)
merge (s:Source {name: a.`source.title`, uri: a.`source.uri`})
create (s)-[:PUBLISHES]->(a);
The result already starts looking nice:
Enrich the news articles with Google's Cloud NLP
I have written about NLP before on this blog (for example when I used Graphaware's NLP tools to analyse Hillary's emails). One of the great applications of the tools is the idea of doing entity extraction: look at a piece of text, and try to identify the entities, concepts, locations, organisations, people, etc that we could usefully derive insights from. This idea is super interesting in a graph: once you look at the text you can then semi-automatically build a knowledge graph from it. And that's what we are going to do here.
To do so, we are going to use the APOC plugin to Neo4j. You can just install this from the Neo4j Desktop in a few clicks. In APOC, there's a fairly recent addition of capabilities that allow you to then CALL EXTERNAL NLP SERVICES, as provided by all the big cloud providers. You can find more information on it on https://neo4j.com/labs/apoc/4.1/nlp/. For the rest of this post, I will be working with the Google Cloud Platform Natural Language Processing API, as exposed by APOC through the functionalities documented on https://neo4j.com/labs/apoc/4.1/nlp/gcp/ .
As mentioned, this uses the Google Cloud Natural Language API - more info to be found over here: https://cloud.google.com/natural-language/ . So to access this, we need to head over to the GCP console, and make some preparations. I created a project, and then went to https://console.cloud.google.com/apis/api/language.googleapis.com/overview?project=<your project name> to do the config.

Using Google Cloud's Natural Language Processing from APOC
One more thing that we needed to do, which is clearly documented on the APOC documentation page, is to install the dependencies on the local Neo4j server: you can find the current versions on https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/4.1.0.6/apoc-nlp-dependencies-4.1.0.6.jar and drop these into the ./plugins directory. Restart the server, and we are ready to rumble and start extending the dataset with entities that Google will automatically extract from the article texts.
First thing to do is to make your Neo4j browser aware of the API key. We set this key in a Browser parameter like this:
and get this confirmed:

Now, before I proceed, I want to document a problem that I had and that I was able to resolve with the help of Tomaz Bratanic - one of our great community members. The thing is that my dataset here contains articles in multiple languages - and Google's NLP engine does not like it when we give it different articles in different languages in the same NLP transaction. It actually throws a very cryptic error:
`Failed to invoke procedure `apoc.nlp.gcp.entities.graph`: Caused by: java.io.IOException: Server returned HTTP response code: 400 for URL: ...`

return a.lang, count(*);
gives me this result:

So that's why I actually had to create a different NLP query (which I would fire to GCP through the APOC call) for every language. Here's what the query looks like:
where a.lang = "<<REPLACE WITH LANGUAGE CODE>>"
CALL apoc.nlp.gcp.entities.graph(a, {
key: $apiKey,
nodeProperty: "body",
scoreCutoff: 0.01,
writeRelationshipType: "HAS_ENTITY",
writeRelationshipProperty: "gcpEntityScore",
write: true
})
YIELD graph AS g
RETURN "Success!";
I can run this query for every language, and get the results back really in less than a minute:

As you can see now, the NLP has done it's magic, and has actually significantly enriched the datamodel with new entities:


No comments:
Post a Comment