So let's take a look at some of these queries.
Some data profiling and exploration
Here's a very simple query to give you a feel for the dataset:
match (n)-[r:LINKS_TO]->(m)return distinct r.type, count(r);match (n) return count(n);
The results are telling:

And so now we can start taking a look at some specific links between pages. One place to investigate would be the Neo4j wikipedia page. Here's a query that looks at the source pages that are generating traffic into the Neo4j wikipedia page:
match (source:Page)-[sourcelink:LINKS_TO]->(neo:Page {title:"Neo4j"})return source, sourcelink, neo;
That gives you a very simple graph:

So what would happen if we would take that one step further, and look at the source pages of the source pages for traffic to the Neo4j website. That's an easy enough variable length path query on Neo4j:
match path = (sourcepage:Page)-[:LINKS_TO*..2]->(neopage:Page {title: "Neo4j"})return pathlimit 100;
That is starting to give you an even richer view:

That's already very cool - but let's continue.
Understanding the importance of the links
Now, in order to understand the importance of these links and paths, we are going to start working with the relationship property quantity that is going to give us a feel for the relative importance of every link. Here's what we'll do:
match (source:Page)-[sourcelink:LINKS_TO]->(neo:Page {title:"Neo4j"})
return source.title, sourcelink.quantity as nrofclicks
order by nrofclicks desc;
This is the result:

And we can actually do that for the links two hops away:
And we can actually do that for the links two hops away:
match (source:Page)-[sourcelink:LINKS_TO*..2]->(neo:Page {title:"Neo4j"})return source.title, REDUCE(sumofq = 0, r IN sourcelink | sumofq + r.quantity) AS totalorder by total desclimit 10;

match (sourceofsource:Page)-[sourceofsourcelink:LINKS_TO]->(source:Page)-[sourcelink:LINKS_TO]->(neo:Page {title:"Neo4j"})return sourceofsource.title+"==>"+source.title+"==> Neo4j" as pages, sourceofsourcelink.quantity+sourcelink.quantity as totalorder by total desclimit 10;
and get this result:

match path = (source:Page)-[sourcelink:LINKS_TO*..2]->(neo:Page {title:"Neo4j"})RETURN [node IN nodes(path) | node.title] as titles,reduce(sumofq = 0, r in relationships(path) | sumofq + r.quantity) as totalorder by total desclimit 10;
This gives you the same result as above, but all of a sudden I can also run this for depts of 4 or more even. Here's the result at dept 2:
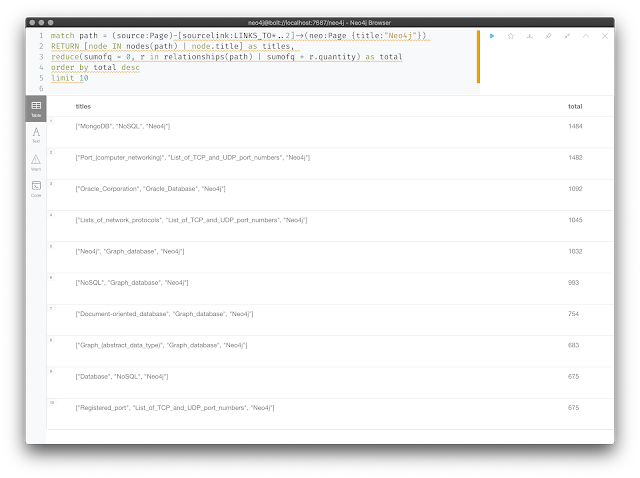

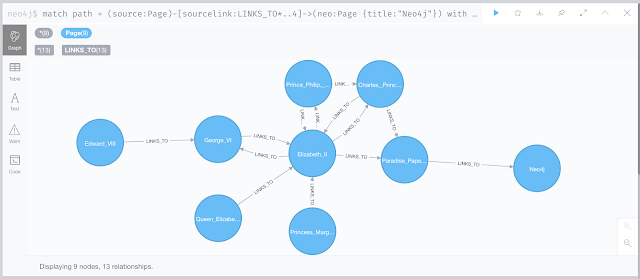
Which highlights a very interesting link between the British royals and Neo4j :) ...
match path = (target:Page)<-[targetlink:LINKS_TO*..4]-(neo:Page {title:"Neo4j"})return reverse([node IN nodes(path) | node.title]) as titles,reduce(sumofq = 0, r in relationships(path) | sumofq + r.quantity) as totalorder by total desclimit 10;
Which then again shows some very interesting outgoing links:

Now before we move to some graph data science exercises, I wanted to highlight one more interesting query problem that I had while doing this exercise - which is all about case sensitivity.
Tackling case sensitivity
One thing I noticed while I was working on the above examples is that it pretty confusing to do some querying that is case insensitive. Take the following example:match (p:Page)where p.title contains "beer"return count(p);
This yields this results:

But this would actually only give me the case sensitive results. I can actually solve this by using regular expressions in my where clause:
match (p:Page)where p.title =~ "(?i).*beer.*"return count(p);
This gives me a much wider result set:

but is also quite a bit less efficient, as it cannot use the Neo4j native indexes to do this matching. This can be a real problem. One solution for this would be to use Neo4j's native support for Lucene indexes, aka the "fulltext indexes". You can actually really easily add these to the index providers, on top of the native ones. You can do this as follows:
CALL db.index.fulltext.createNodeIndex("pagetitleindex", ["Page"], ["title"]);
This adds the index to the database, as you can see below.

So there we have 2 different indexes, one native (used for the uniqueness constraint, as well), one fulltext, on the same Label/Property.
So there we have 2 different indexes, one native (used for the uniqueness constraint, as well), one fulltext, on the same Label/Property.
Now, in order to do a case insensitive query, we can actually use that fulltext index to do the lookup, instead of the above regular expression based solution.
CALL db.index.fulltext.queryNodes("pagetitleindex", "*beer*") YIELD node return count(node);
The result is the same as the one we had above, but it is way more efficient!

Here's a sample of what the results actually look like:
CALL db.index.fulltext.queryNodes("pagetitleindex", "*beer*") YIELD node, scoreRETURN node.title;

You can clearly see that this is no longer case sensitive! Great!
That covers part 2 of this blogpost series. In part 3 we will start looking at some graph data science on this dataset - which should be a ton of fun as well.
Hope this was useful - as always comments very welcome.
Cheers
Rik
PS: all scripts are nicely put together on github.
No comments:
Post a Comment