
This is: I really want to look at this data as a GRAPH - not a table. Of course, you say...
The GraphConnect Schedule Spreadsheet
In orde to do that, we create a nice little spreadsheet version of the schedule first. Simple, in a Google Sheet: here it is. It really is pretty simple:
And of course, like with every Google Sheet, it's trivial to download it as a CSV file. Here it is straight from Google (you have to make it public - which I have done - for this to work, of course), or find it in the Github Gist as well. And then of course, we can start importing the data into Neo4j.
Importing the Schedule into Neo4j
Like with previous conference schedule imports, I have chose then same model again to import the data into:
So we have 2 days (25th for the trainings at CodeNode, and 26th for the conference at QE2 centre), lots of timeslots in each day, and then Sessions that are part of tracks, located in Rooms, held by Persons that work at Companies). Pretty straightforward!
So then we have a an import statement (or a series of different import statements - whatever you prefer) to get the data into this model. I have put both versions (the single statement, and the multi-statement version) in this Github Gist, but I will share the single statement version over here:
load csv with headers from "https://docs.google.com/a/neotechnology.com/spreadsheets/d/10sswmRmY5FjYMLU5c5rJlXr4m9Idxw7tC8OImb7v4Yg/export?format=csv&id=10sswmRmY5FjYMLU5c5rJlXr4m9Idxw7tC8OImb7v4Yg&gid=16326967" as csvmerge (d:Day {date: toInt(csv.day)})with csvmatch (d:Day), (d2:Day)where d.date = d2.date-1merge (d)-[:PRECEDES]-(d2)with csvmerge (r:Room {name: csv.room})merge (t:Track {name: csv.track})merge (p:Person {name: csv.speaker, title: csv.title})merge (c:Company {name: csv.company})merge (p)-[:WORKS_FOR]->(c)with csvmatch (d:Day {date: toInt(csv.day)})merge (t1:Time {time: toInt(csv.starttime)})-[:PART_OF]->(d)merge (t2:Time {time: toInt(csv.endtime)})-[:PART_OF]->(d)with csvmatch (t2:Time {time: toInt(csv.endtime)})-[:PART_OF]->(d:Day {date: toInt(csv.day)})<-[:PART_OF]-(t1:Time {time: toInt(csv.starttime)}), (r:Room {name: csv.room}), (t:Track {name: csv.track}), (p:Person {name: csv.speaker, title: csv.title})merge (s:Session {title: csv.talk})merge (s)<-[:SPEAKS_IN]-(p)merge (s)-[:IN_ROOM]->(r)merge (s)-[:STARTS_AT]->(t1)merge (s)-[:ENDS_AT]->(t2)merge (s)-[:IN_TRACK]->(t);As you can see, it's basically different statements tied together by a bunch of WITH statements. Try it out on your local machine, and it should work. If it does not, then you can always go back to the multi-statement version - that definitely works, also on older versions of Neo4j.
Querying the Schedule Graph
Of course then we like to explore the graph, right. I have created a few queries for you to play around with - they are also in the Github Gist - but let's start by taking a look at day 1 with a simple query:match (d:Day {date:20160425})<--(t:Time)<--(s:Session)--(connections)return d,t,s,connectionslimit 50Gives you a very nice and graphy view of the trainings:
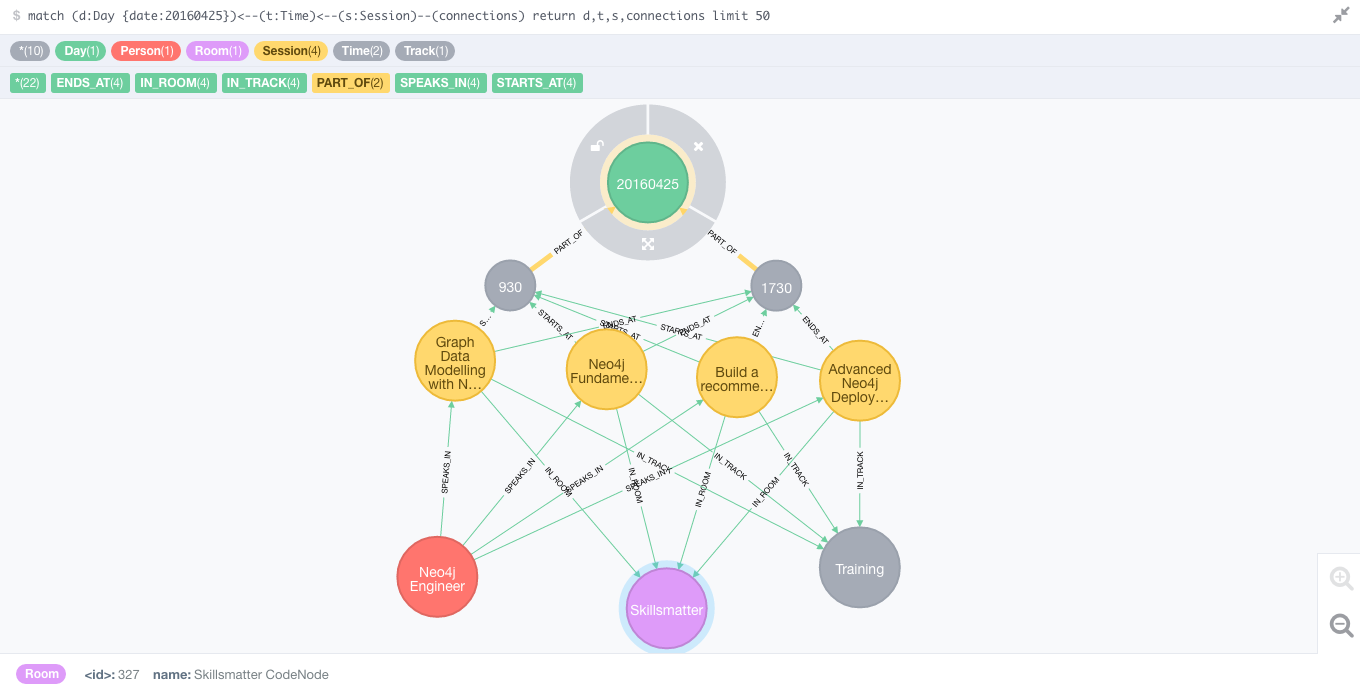
Obviously this would be a bit more of a complicated graph - because of the more varied schedule, of course - for day 2:

And that's just a sample! But one part worth looking into are some of the talks that will be given by the MOST FAMOUS user of Neo4j these days, the ICIJ. Since the publication of the Panama Papers, they have been front page news - and clearly this will get a lot of attention at GraphConnect as well:

And then we can start asking some truly "graphy queries: how would our beloved Dr. Jim Webber be related to the ICIJ? Let's ask the graph:
match (c:Company {name:"ICIJ"}), (p:Person {name:"Jim Webber"}),path = allshortestpaths( (c)-[*]-(p) )return pathThis gives you this result:

That's about it for now. I hope you will play around with the Schedule Graph yourself as well, and I look forward to seeing you at the conference.
All the best
Rik
No comments:
Post a Comment