In this blogpost, I will be focussing on one of the integrations that could be very useful for non-technical, end-user computing style people like myself. I have blogged before about how you can use a spreadsheet to import data into neo4j, but now, what I would like to demonstrate here is how easy it is to generate a spreadsheet with data that is coming straight from a neo4j cypher query. Let’s say that I have a complex query, one with multiple “joins” and that I am using neo4j to get neo4j to get some decent performance on these queries.
So what do I need:
 a running neo4j database. I will use my beergraph as a dataset and run some of these queries as examples.
a running neo4j database. I will use my beergraph as a dataset and run some of these queries as examples.- the jdbc driver. Download the binaries and install them. Dead simple. Detailed instructions are on the github page.
- NeoOffice (a Mac-savvy fork of LibreOffice/OpenOffice - which coincidentally shares the first three letters with my favorite database ;-)) to open up the jdbc connection and then fire of the Cypher queries.
Let’s dig right in.
Three Steps
In order to successfully use the jdbc driver from neooffice to generate the speadsheet, there are essentially two steps:
- the “database” step: this creates a neooffice database (this is the equivalent of an MS Access database) and registers the connection to neo4j via the jdbc driver as a datasource. It will allow me to define the queries that I want to run, test the results, and prepare for using these queries in the neooffice spreadsheet.
- the “spreadsheet” step: use the datasource that we defined above, and easily get stuff into the neooffice spreadsheet for further investigation, manipulation and reporting - the things that people typically do in their spreadsheets.
- the “end-user computing” step: how can I then start doing typical spreadsheet operations, straight onto the neo4j database.
Let’s go through this step by step and show you how easy it is.
Step 1: the Database step

Let’s assume that you have your neo4j server running on your localhost, and that you have loaded the beergraph dataset.
In NeoOffice, we then have to create the connectivity to this running server, by creating a database document. In that creation process, you will then have the option to connect to an existing database through JDBC, as you can see in the screenshot below:

Next, you will have to register two things:
- the Datasource URL: this should be neo4j://localhost:7474, or a different hostname/portnumber if your neo4j instance is not running on the your local machine / the default ports.
- the JDBC driver class: this should be org.neo4j.jdbc.Driver. You can push the “Test class” button to see if the connection was correctly installed. Should be easy.

START
beerbrand=node:node_auto_index(type="BeerBrand")
MATCH
beerbrand-[:IS_A]->beertype,
beerbrand-[:HAS_ALCOHOL_PERCENTAGE]->alcperc,
brewery-[:BREWS]->beerbrand
RETURN
beerbrand.name as BeerBrand,
beertype.name as BeerType,
alcperc.name as AlcPerc,
brewery.name as Brewery;
Running this query in the neo4j-shell gives you something like this:

Running this query in the neo4j-shell gives you something like this:
 Let’s copy and paste that into the query window, save, give the query a name (in our case "wiki"). Please do remember to push the little “Run SQL Command directly” button , as it will deal with the fact that … we are not running SQL, but indeed using Cypher over the JDBC connector.
Let’s copy and paste that into the query window, save, give the query a name (in our case "wiki"). Please do remember to push the little “Run SQL Command directly” button , as it will deal with the fact that … we are not running SQL, but indeed using Cypher over the JDBC connector.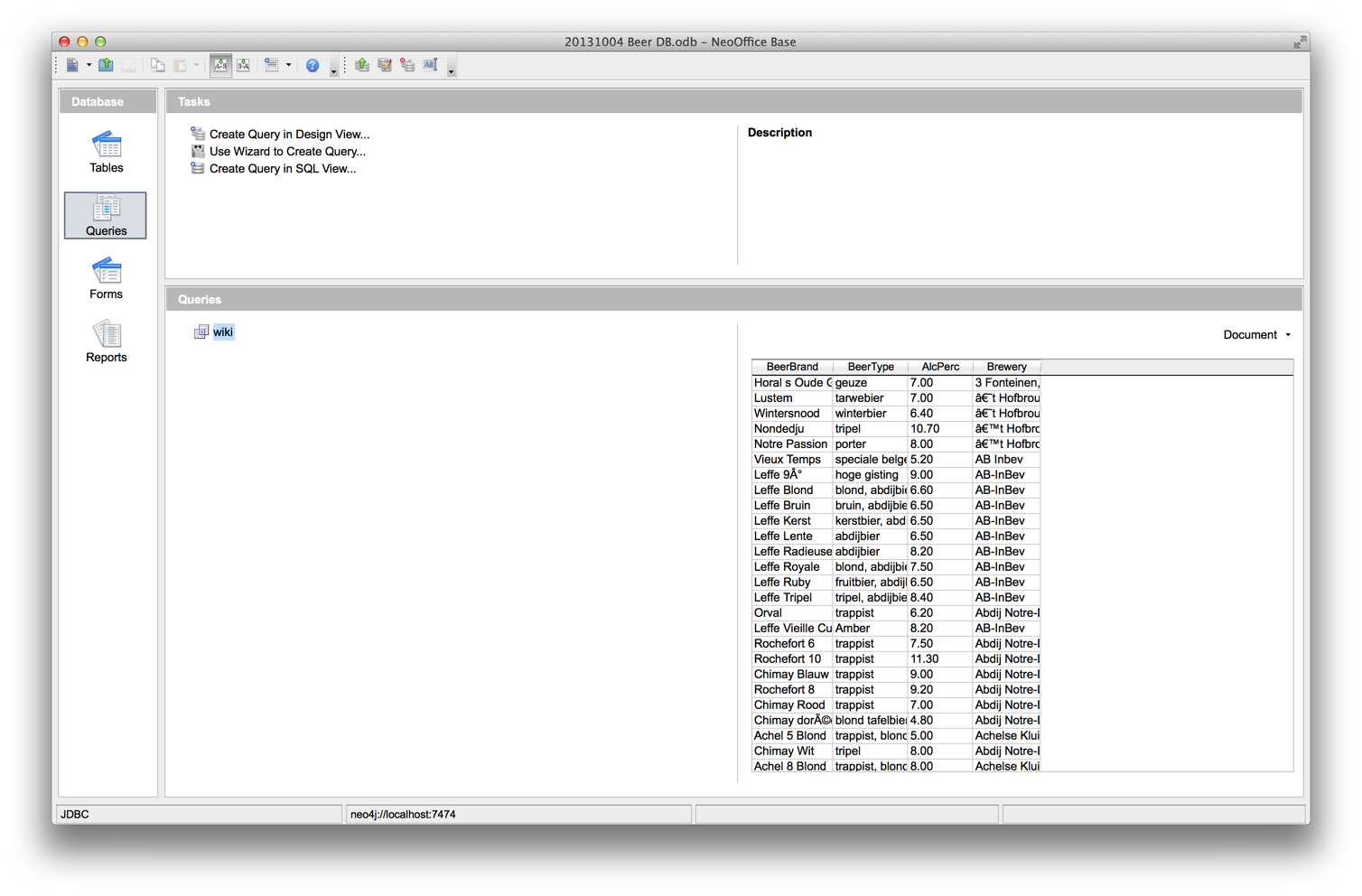
If you then try out the query by double clicking it in the main database window, you should get something very similar to what we are looking for:
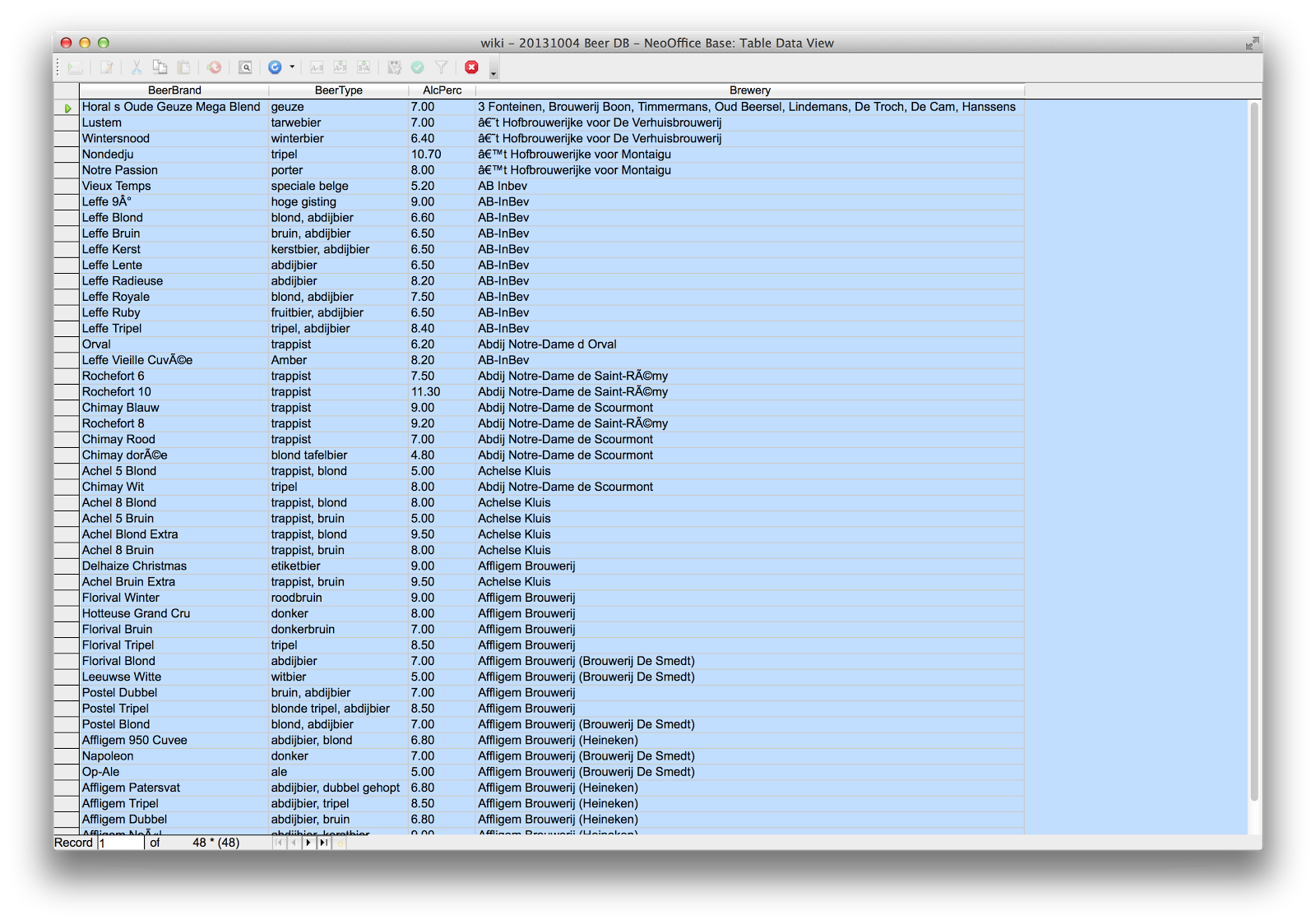
So that completes the first step of this exercise. We have our JDBC connectivity set up between the NeoOffice database and neo4j, and a working query to play around with. Now for the spreadsheet part.
 Step 2: the spreadsheet step
Step 2: the spreadsheet step
This second part is actually terribly easy. All we need to do is
- in the “View” menu of the spreadsheet, we enable the “Data Sources” view. This will then open up a “database” window within the spreadsheet document. Our newly created database - see step 1 above - should now appear in the list of datasources, and our query (in my example, I called the query “wiki”) should also appear as soon as you fold the queries open.
- create a new spreadsheet document
- simply double-clicking the query now gives you access to the query results, within the spreadheet’s top window
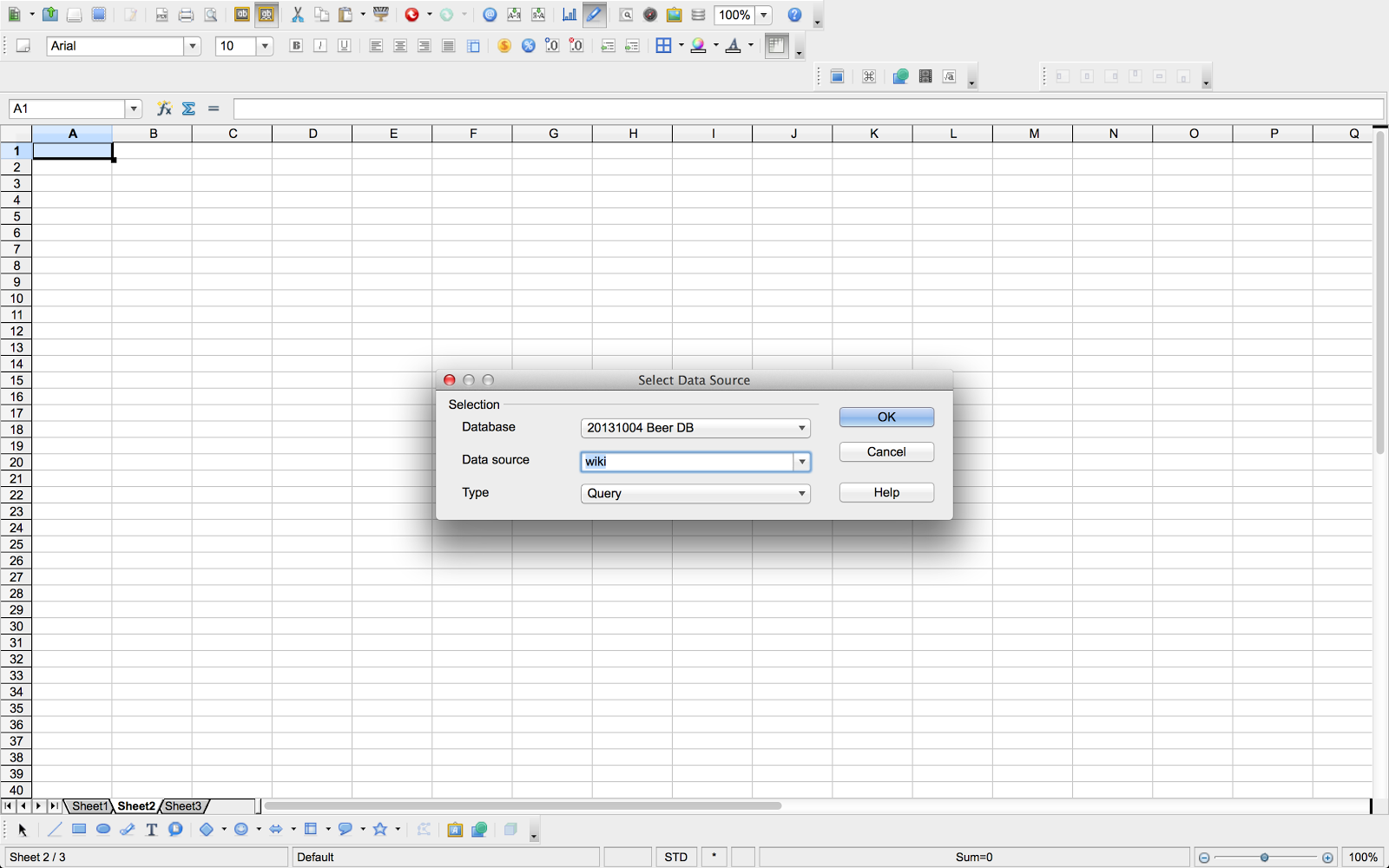
 The remaining step then, is to copy the query result data into the spreadsheet cells. There’s two ways to do that:
The remaining step then, is to copy the query result data into the spreadsheet cells. There’s two ways to do that:- select the query results in the top right window, position the spreadsheet cursor in the cell that you want the data to go to, and then click the “Data to Text” button
- just grab the query name (top left sub-window) and drag it to the cell that you would like to put it in

{kind=link}
Step 3: the end-user computing step
A logical final step then, is to allow the connectivity and spreadsheet integration that we demonstrated above, to do end-user spreadsheet manipulations, like creating a PivotTable/DataPilot sheet that allows me to better understand my dataset.
NeoOffice has a very easy interface to do these things: just start the DataPilot wizard from the “Data” menu in the spreadsheet, and click “Start”.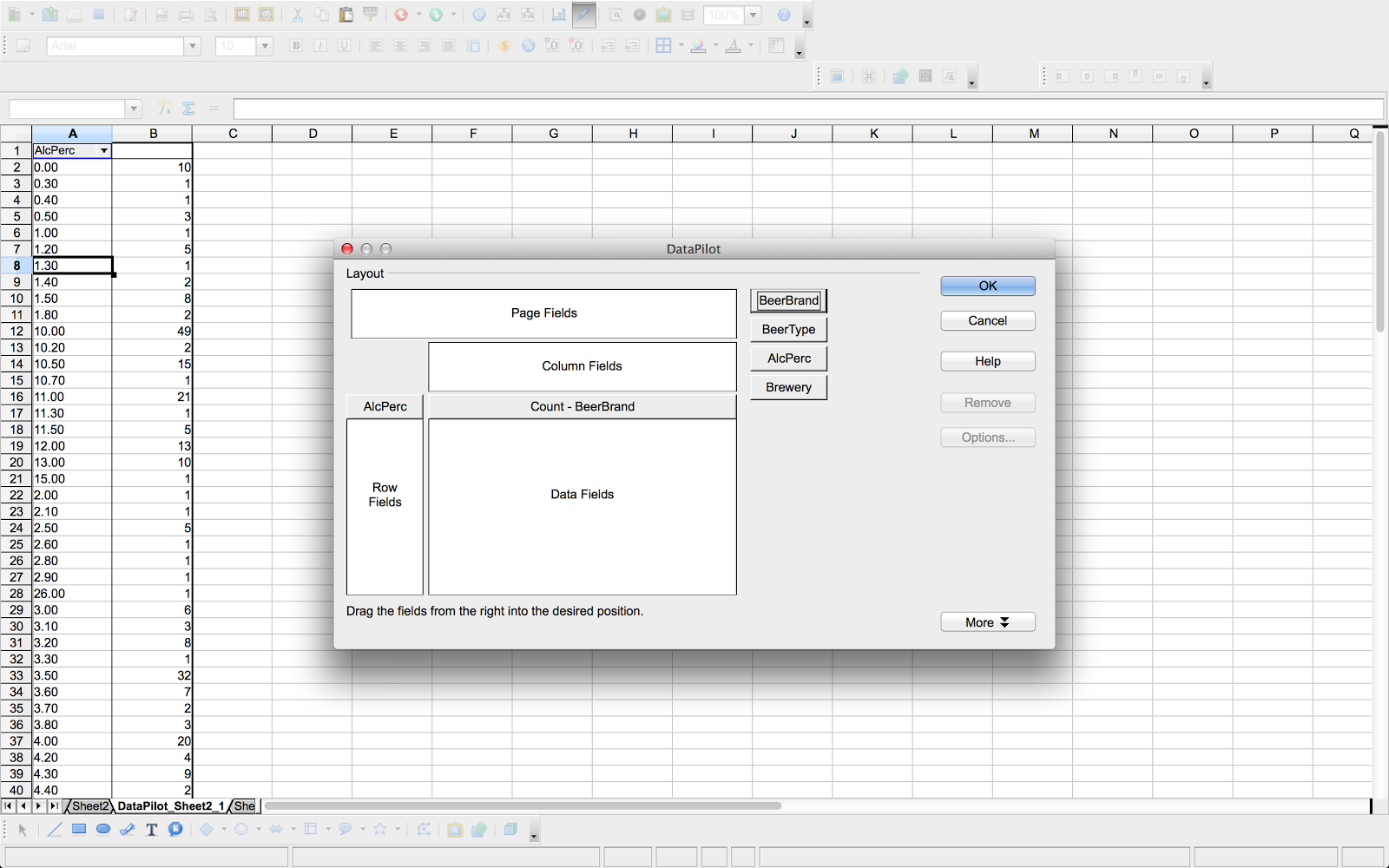
Then, we reuse the work we did above, and select the registered datasource to base our work of.
The “wiki” query that we executed above, is available under the “query” section, and we can then proceed to the actual construction of the pivottable. We do this by dragging the appropriate “fields” (columns in our cypher resultset) onto the different parts of the pivottable. Once we are ready, we get the following, dynamically composed graph summary table.
I am sure that there are many other things that you can think of doing this way.

Conclusion
I hope that in this post, we have given you a good overview of how you can integrate a traditional software package like NeoOffice/OpenOffice with an advanced, graph-based datastore like neo4j. The possibilities of this connectivity are endless - and we wish you happy hours of data exploration to come.
All the best
Rik
No comments:
Post a Comment