Labels are simply fantastic in my opinion. You can read up on the advantages that they bring, now and into the future, over here. But what does it mean to some of my previously generated neo4j databases? Well - turns out it's quite a thing. Not that the actual upgrade of the datastore is difficult (it's as simple as uncommenting the "allow_store_upgrade=true" line in the neo4j.properties file), but how could I actually start taking advantage of the labels feature, in my datamodel, in my queries, in the fantastic new neo4j browser? Let's find out.
Revisiting my Last.fm model
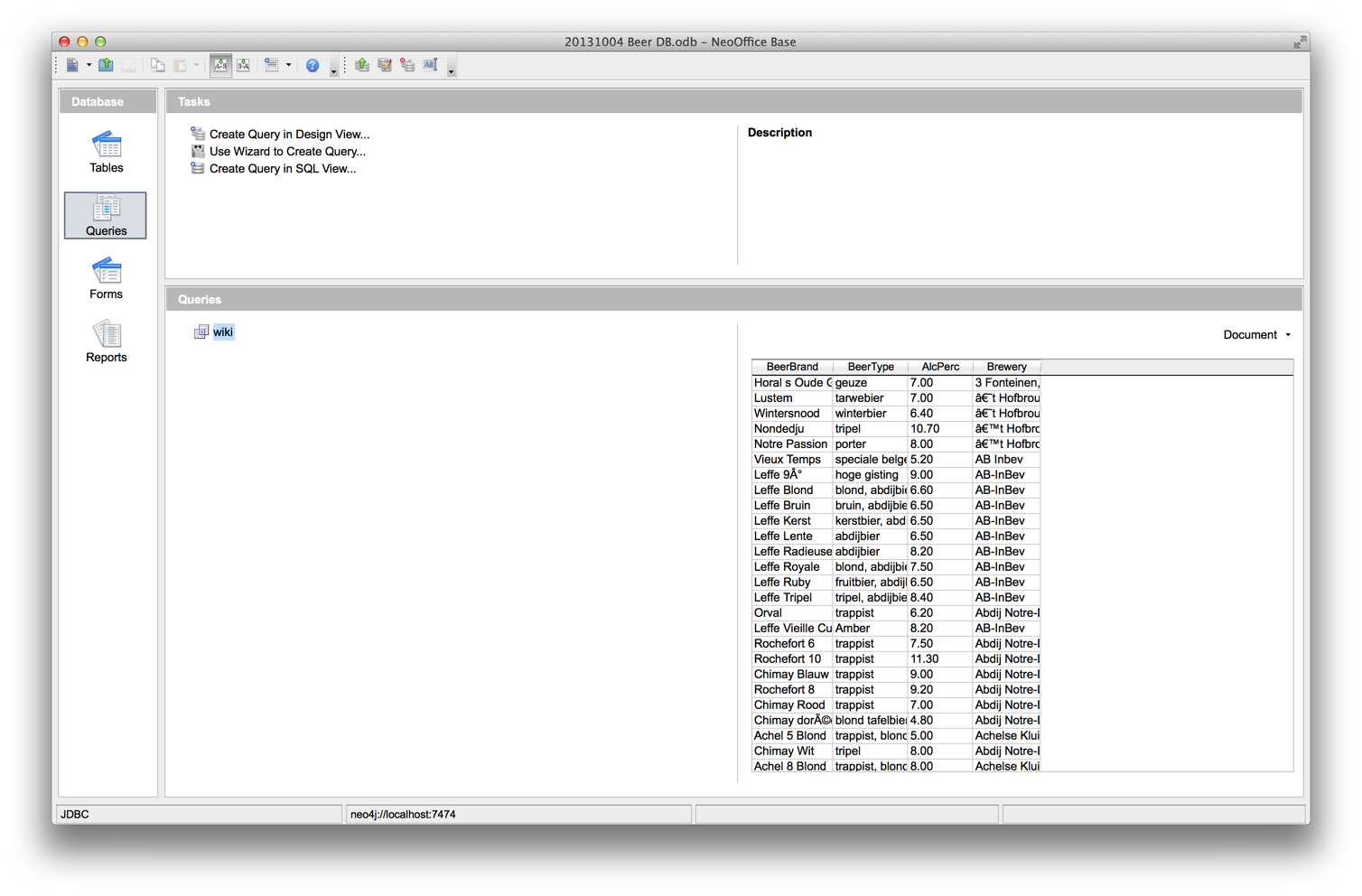
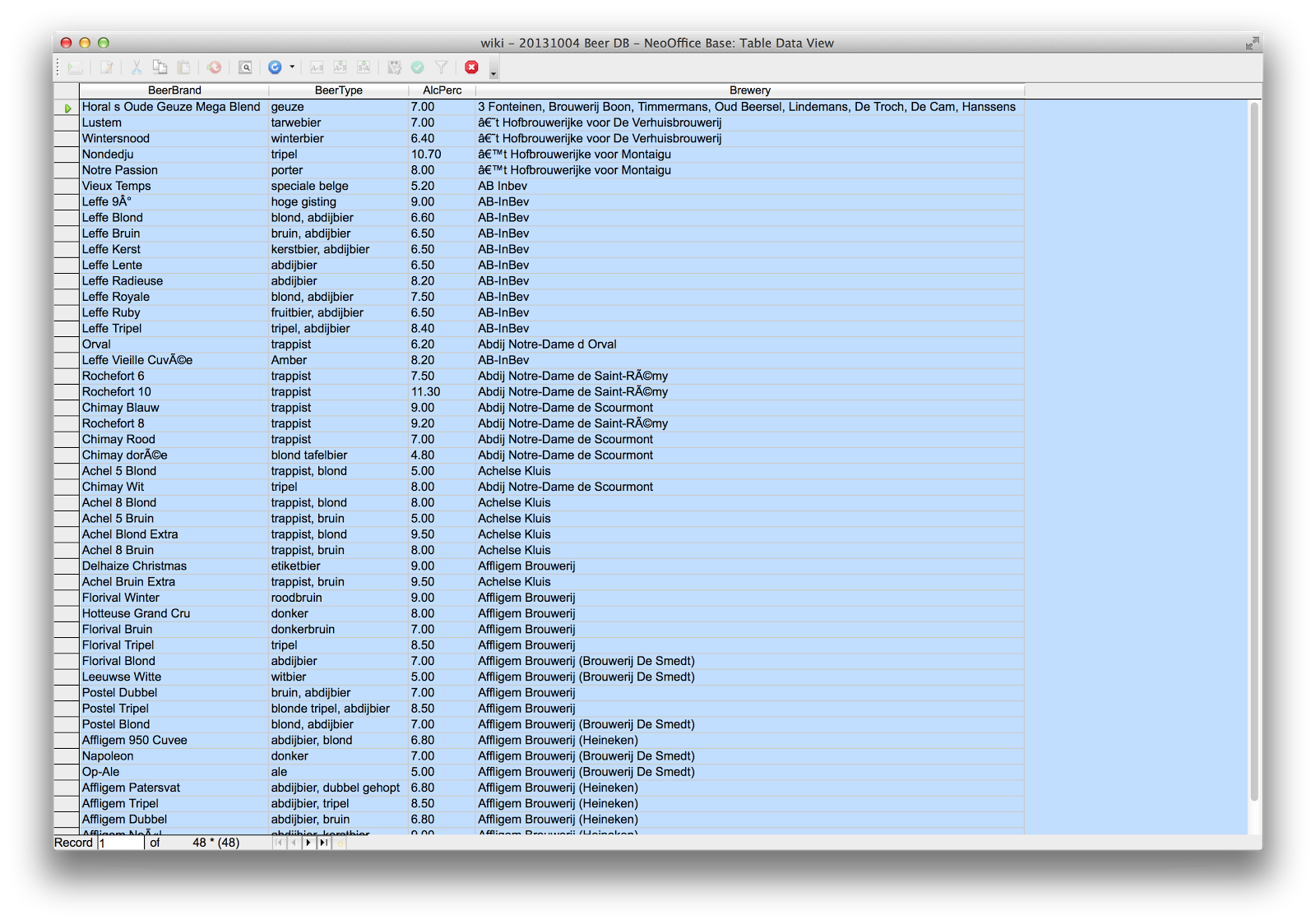
In my previous blog posts, I had imported a last.fm scrobbling dataset using different methods. The model looked something like this:
In all of the nodes of that model, I had included at minimum two properties: a "name" and a "type". So guess what: it makes total sense to convert these "type" properties into labels, ending up with 6 different subgraphs based on the labels: listeners, scrobbles, tracks, artists, albums and dates. Nice. I will be able to use the new, improved indexing that neo4j 2.0 features based on these labels, of course.
Re-importing the data from the same .csv files
So then I need to recreate the database reflecting this change. My source files (see the previous blogpost: just download from here) are of course the same - all I need was a slightly modified import process. My dear friend Michael Hunger has already prepared a 2.0 version of the neo4j-shell-tools - and they just work like a charm.
Here are the import statements for the nodes:
import-cypher -d ; -i ./IMPORT/INPUT/nodespart1.csv -o ./IMPORT/OUTPUT/1out.csv create (n:#{type} {name:{name}}) return n.name as name
import-cypher -d ; -i ./IMPORT/INPUT/nodespart2.csv -o ./IMPORT/OUTPUT/2out.csv create (n:#{type} {title:{title}, name:{name}}) return n.name as name
As you can suspect, the n:#{type} piece is the interesting part. This is where we use the "type" data-element from the csv files for the labels, not for the old "type-property". The reason why the # is there is because Michael had to do some wizardry to allow for parametrized labels - which is normally not supported in Cypher.
Adding indexes based on Labels
Before we now go and import the relationships, we have to add the indexes on these newly created nodes and labels. We do that as follows in the neo4j-shell:
CREATE index on :date(name);
CREATE index on :album(name);
CREATE index on :scrobble(name);
CREATE index on :listener(name);
CREATE index on :artist(name);
CREATE index on :track(name);
This takes a second or two. but once complete, we can see that the indexes are ready to be used by typing the schema command:

And then we can proceed to import the relationships, again with the same .csv files.
No longer starting with a start
Importing the relationships is also done with neo4j-shell-tools, but slightly different from last time: the parametrized cypher queries no longer "start with a START", they now start with a "MATCH". This is because, now that indexing has become an integral part of neo4j, you can really work with Cypher in an even more declarative fashion than before. You don't have to imperatively tell the database where to start - it will figure it out for you based on the pattern that you specify.
Here are the new import statements:
import-cypher -d ; -i ./IMPORT/INPUT/APPEARS_ON.csv -o ./IMPORT/OUTPUT/3out.csv MATCH (track:track), (album:album) where track.name={mbid1} and album.name={mbid2} create unique track-[:APPEARS_ON]->album return track.name, album.name
import-cypher -d ; -i ./IMPORT/INPUT/CREATES.csv -o ./IMPORT/OUTPUT/4out.csv MATCH (album:album), (artist:artist) where artist.name={mbid1} and album.name={mbid2} create unique artist-[:CREATES]->album return album.name, artist.name
import-cypher -d ; -i ./IMPORT/INPUT/FEATURES.csv -o ./IMPORT/OUTPUT/5out.csv MATCH (scrobble:scrobble), (track:track) where scrobble.name={scrobble} and track.name={mbid} create unique scrobble-[:FEATURES]->track return scrobble.name, track.name
import-cypher -d ; -i ./IMPORT/INPUT/LOGS.csv -o ./IMPORT/OUTPUT/6out.csv MATCH (listener:listener), (scrobble:scrobble) where listener.name={user} and scrobble.name={song} create listener-[:LOGS]->scrobble return listener.name, scrobble.name
import-cypher -d ; -i ./IMPORT/INPUT/ON_DATE.csv -o ./IMPORT/OUTPUT/7out.csv MATCH (date:date), (scrobble:scrobble) where scrobble.name={song} and date.name={date} create scrobble-[:ON_DATE]->date return scrobble.name, date.name
import-cypher -d ; -i ./IMPORT/INPUT/PERFORMS.csv -o ./IMPORT/OUTPUT/8out.csv MATCH (artist:artist), (track:track) where artist.name={mbid1} and track.name={mbid2} create unique artist-[:PERFORMS]->track return artist.name, track.name
import-cypher -d ; -i ./IMPORT/INPUT/PRECEDES.csv -o ./IMPORT/OUTPUT/9out.csv MATCH (date1:date), (date2:date) where date1.name={date1} and date2.name={date2} create date1-[:PRECEDES]->date2 return date1.name, date2.name
You can download the entire set of statements from over here.
So there we have it: a newly imported, nicely labeled neo4j-2.0 dataset. So let's fire up the browser and see what the result looks like?

Very nice! Now I can start playing around to my hearts' content with the new browser and have even more fun. How is that even possible?
Hope this was useful. Until next time.














{kind=link}