
I have written before about some of the important paradoxical tendencies in the Machine Learning (ML) and Intelligence (AI) industries. Let’s look at it from two perspectives:
- The Developer: the top engineer that is trying to help his or her organization move forward, by using ML and AI techniques.
- The CTO: the engineering manager that is trying to oversee these efforts, and who wants to ensure that they are pursued in a technologically and economically/budgetary sound way - while complying with all the new rules and regulations that are now forthcoming.
It should be clear that these are two important, decisive, even, perspectives that can truly determine the success or failure of AI/ML projects. Therefore, we’d like to zoom into these two perspectives in a little more detail, and then explore what the impact of openness and modularity could be on the context of these two personas.
The Developer's Context
For developers working on these types of AI/ML software projects, I think we can state some universal truths:
- developers don't like architectural overhauls
- developers are opinionated about the tools that they like and use: they want to be productive, and because of this they usually prefer to stick to the tools that they know.
At the same time: we know that data scientists and machine learning engineers spend a lot of time on setting up and managing the tools in their technical work environment. See
the 2022 Kaggle survey: data scientists spend 50-80% of their time on their environment, data engineers spend 30-40% of their time on maintaining their pipelines, ML Engineers spend 20-30% of their time on this. All of this time is being spent on If we can cut the time spent on non-core ML and AI tasks by 10%, we will make a massive win for the organization and the individual contributor.
The CTO's Context
For CTO’s that are working on AI/ML software projects, we can also consider some universal considerations:
- The CTO is responsible for making sure that his organization is constantly innovating and adding value to the business. AI and ML seem to offer massive potential for innovation for many organizations: we want to seize the opportunity, before our competitors do so. If the CTO does not act proactively, there will be a CxO on the management team that will start asking questions about the potential of AI shortly - you can bet your house on that.
- Exceptionally, this is done with "big bang" solutions that will radically change an entire architecture from scratch, in a greenfield.
- However, most people don't work in a greenfield, they work in a brownfield. Therefore, big bang approaches are not possible, and most people and organizations turn to innovate in different small incremental steps.
We know that all this work will have to be done in an economically sound and feasible way. See the
SpringerLink Study and the McKinsey
State of AI report - both stressing the need for cost efficiency in AI and ML systems.
So: in assessing both of these perspectives, we are clearly presented with an important question: how can we figure out a way to
incrementally innovate using AI/ML,
provide value to our organization in an economically sound manner, while
respecting the productivity requirements and
current tool choices of our engineers as much as possible?
The importance of Openness and Modularity
As I have tried to explain how both the individual engineer and their CTO management have at least slightly conflicting interests in the implementation of AI and ML projects. How can we make this work then? Here’s where I think we can take a look at the software industry in general, and look at some of the technological and methodological approaches that have made software engineering so much more productive in recent years.
To do so, let’s think back to where we came from: as little as two or three decades ago,
waterfall-based software engineering methodologies were the standard for how you would tackle large software projects. It took books like the
Mythical Man-month and the
Agile Manifesto to emerge for people to start changing their approach, and to start developing and then using
iterative software engineering methodologies,
DevOps practices,
Infrastructure-as-Code and cloud computing as critical enablers of a more modern approach. This is what we need to apply in the world of the very specific domain of AI and ML now: we need to learn how to apply these techniques in the world of AI and ML, and that will require a specific architecture to enable this.
This architecture should therefore
- NOT be a closed, all-or-nothing environment,
- NOT limit the engineers to a specific toolset,
- NOT bound you to a specific deployment environment, offered by this that or the other cloud vendor
- NOT dictate the specific framework that you should or should not use for your AI and ML
On the contrary - our vision here should be for an open and modular architecture that would allow for us to leverage the power of AI and ML in an incremental, balanced way. Like in general software development best practices, this architecture will enable a combination of tools and processes that will propel AI and ML projects forward, and resolve the paradox that we have seen emerge.
Let’s discuss this vision in a bit more detail. We’ll call this the Incremental AI Architecture (AIAI), enabled by the AI Lakehouse.
The Incremental AI Architecture (IAIA)
Today, many AI and ML projects are characterized by structures that are very different from what we want in an innovative and incremental AI Architecture. Systems are developed with bespoke tools and processes that are specific to the project in which they are implemented, and do not allow for reuse and automation in a way that an IAIA enabled by an AI Lakehouse would. Therefore, we propose a combination of best practices and tools that will allow you to move in this direction.
Let’s walk through the different steps in a few succinct paragraphs.
Start with modularization of pipelines:
At Hopsworks, we have argued many times before that one of the first steps that one should take when embarking on an AI/ML project, is to conceptually break up the AI/ML system into three parts. We refer to these three parts as the
“F-T-I” pipelines, where we would distinguish three distinct phases and processes in the development and productionalization of these systems. At a high level, we would consider
- The Feature Pipeline, where the different data sources of the input data of the AI/ML system are wrangled into the right format(s), and then eventually persisted in a way that would enable the next “T” phase of the system to proceed.
- The Training Pipeline, where the input features would be used to train and test a an AI/ML model that would be used for making the predictions that we need for our organization.
- The Inference Pipeline, where we deploy the model that was generated by the training pipeline, and start using it to allow systems and applications to use it’s capabilities and serve the predictions of the model to the outside world. In this pipeline, we would also want to monitor for any impactful changes inside or outside the system that would warrant us to revisit the process.
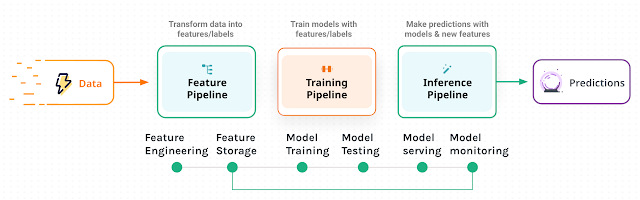
Once we have split the AI/ML system into these three functional and modular parts, we can proceed to take the next step to make the system into a true production-ready AI system. This will require some education of our team, and that would be the important second step in this journey.
Educate the team on the importance of MLOps for production AI systems
In order to maximize the benefits of AI systems in production, we will need to automate as many of the FTI pipeline steps as possible. This is what we call
MLOps, short for “Machine Learning Operations” and analogous to
DevOps.
These automations will offer
- Significant Engineering and Technical benefits that will allow us to write better software systems
- Process benefits that will allow these improved systems to be seized and maintained
- Budgetary and Financial benefits: both our operational expenditures (OpEx) and our capital expenditures (CapEx) can be reduced, enabling more innovation at a lower cost.
Once we have the team on board, we can start looking at an implementation of a professional MLOps platform - and to choose one that allows for a gradual, incremental implementation to accommodate the concerns of the Developer and the CTO.
Do a gradual implementation of an MLOps platform
Over the years, Hopsworks has gained a lot of experience with the implementation of AI/ML systems on top of an MLOps platform, and as a consequence we have developed and released the 4.0 release of the Hopsworks Enterprise platform. We have called this the “AI Lakehouse” release, as we believe that it allows for a comprehensive but gradual implementation of everything an AI/ML project needs to become successful.
Based on this experience, and using the AI Lakehouse infrastructure, we recommend that you consider the following steps in sequence:

- Implement and automate the FTI pipelines on the Feature-store platform. As you can see from the graphic above, all of the pipelines of the recommended F-T-I approach will leverage this central infrastructure, and therefore drive all users and stakeholders of the AI/ML system towards a centralized approach that will be much easier for the Alpha Developer, manageable for the Empowered CTO, and governable for the architects and compliance teams that are to ensure that rules and regulations are appropriately followed.
- Implement a model registry, thereby accurately keeping track of all the impacts and changes that are required of our production AI/ML systems. If necessary, you could combine the registry with an experiment tracking system - but we have found this to be largely unnecessary if the above steps are duly implemented. Once you have the FTI pipelines connected to a feature store, tracking experiments becomes pure overhead.
- Implement centralized model deployment for offline, batch use cases, as well as for online, real time use cases.
- Finalize with centralized feature and model monitoring, iterating back to the FTI pipelines whenever such monitoring demonstrates the need for updating and adaptation.
Last but not least, and in order to ensure solid future implementation of additional AI and ML systems in your organization, you should leverage the above architecture to measure the business results of the AI system implementation. If you do so, chances are that this will be fueling additional investments into the technology, bringing better prediction services to our organizations and a more competitive market position as a result.
Wrapping up
With that, we hope to have made the case for open, modular AI and ML infrastructure more clearly. At Hopsworks, we live and breathe this philosophy day in and day out, and we would love to help you see its power for yourself and your business. Please reach out to us if you have any comments or questions - we will be happy to help out.





























