Why you need a feature store, why you should buy (not build) one, and why you should consider HopsworksStart with 3 Why’s
Quite a few years ago, I read a really intriguing book by Simon Sinek:
Start with Why. The subtitle actually gives away the essence of the book: How Great Leaders Inspire Everyone to Take Action. Spoiler alert: they do so by explaining WHY something needs to get done, before explaining how and what needs to get done. It’s a very simple, but in my experience, important and intuitive way to effectively communicate something to any audience. Whether you are communicating to customers, co-workers or your kids - the WHY usually paves that way for much smoother discussions and actions. Sinek talks about the Golden Circle, which outlines how starting from the inside (why) and working towards the outside (what) is an effective method of any communication strategy.
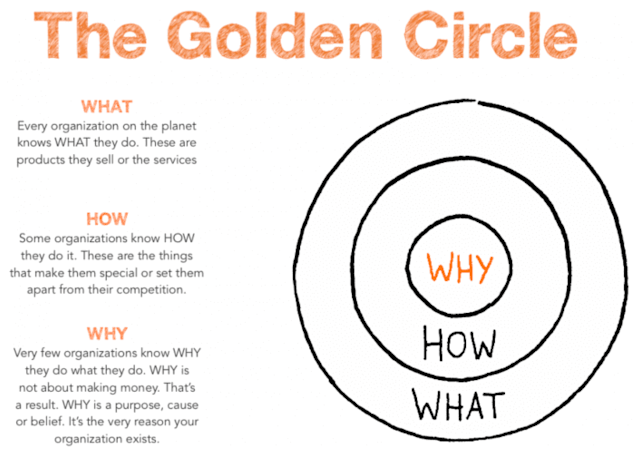
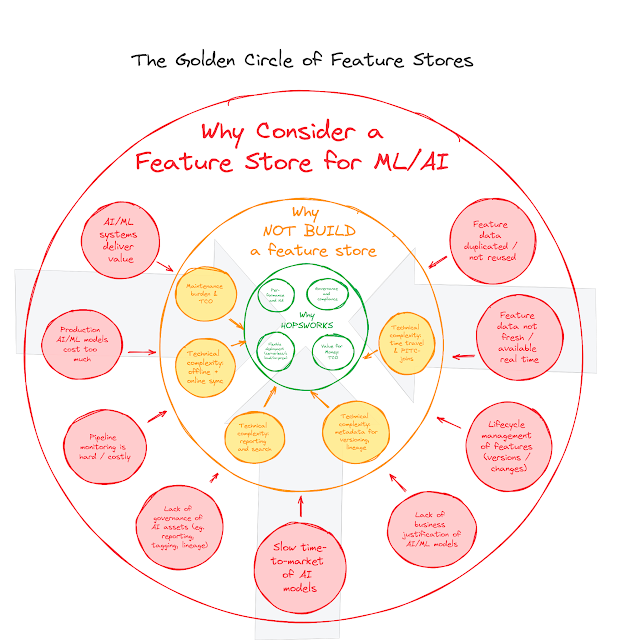
Since I started working for Hopsworks, I have had this framework in the back of my mind, as I got to talk to many more users, customers and partners that have been adopting the amazing technology that the team has built. In these discussions, it actually became clear to me that there are three different “WHY” questions that we need to answer for our community, if we want to be successful in the marketplace. At the risk of misusing the golden circle visualization, I have tried to put these 3 questions in 3 concentric circles in the figure below:
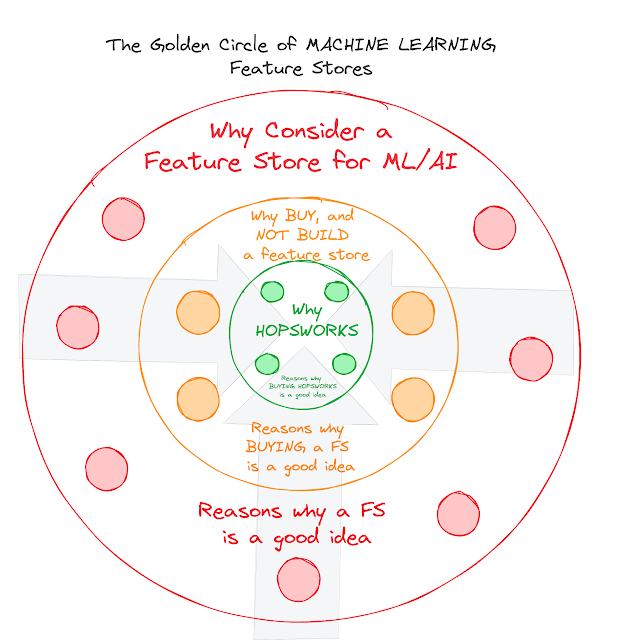
As you can see, you move from the OUTER circle to the INNER circle, and you try to address the following 3 questions:
- Why would you consider using a feature store architecture in the first place? If you would find enough solid reasons for doing so, you would proceed to the next “Why” question, being:
- Why would you NOT BUILD, but instead BUY a feature store for your data platform architecture? And if you find enough reasons to BUY and not build, then you would consider the last and final “Why” question, being:
- Why would you specifically choose to buy the Hopsworks feature store for your data platform architecture?
If, and only if, we understand the potential answers to these questions, in all their variations, can we successfully meet the customer’s expectations and provide value in their implementation. That’s the core idea behind this thought process.
So let’s explore these three WHY questions, and their answers, in a bit more detail.
1. Why Consider a Feature Store for ML/AI?
It’s pretty clear that not everyone needs a Feature Store. A data platform like that is quite specific to the ML/AI workloads, and would only realistically be required or used by organizations and teams that have quite a deep understanding and investment into the relatively new fields of machine learning and artificial intelligence. If all you have in your environment is an early stage experiment with ML/AI technology, then most likely you do not yet have a need for a feature store - seems logical, right? So: what are the conditions under which you would want to consider it? What are the reasons for implementing a Feature Store in your organizations? Let’s explore this!
Many of these reasons were actually outlined in an
earlier article on the
Hopsworks Blog, and I believe that the reasons for considering a Feature Store are accurately described there. In this overview, I would like to make the distinction between technical and non-technical (as in, business / organizational / competency-related). Let’s dig into it:
- Technical reasons for considering a feature store:
- Existing models running in production are expensive - they are hard to debug, review and upgrade, they are bespoke systems that are difficult and costly to maintain. There’s a growing body of evidence that ML/AI systems that do NOT have a feature store architecture in the backend, are simply too expensive because of that - see other points.
- Monitoring production pipelines is challenging, or impossible. The data that powers AI changes over time, and identifying when there are significant changes that require retraining your AI is not easy.
- Difficulties in managing the lifecycle of feature data, including the tracking of versions and historical changes. This is an elementary requirement for all regulated data processing environments - and a key reason why feature stores align so well with these industries’ requirements.
- Feature data is not centrally managed; it is duplicated, features are re-engineered, and generally data is not reused across the organization.
- Non-technical reasons for considering a feature store:
- Valuable models are created but once the experimentation stage is over they do not bridge the chasm to operations - the models do not consistently generate revenue or savings. This is all about getting the models to deliver value, consistently.
- No cohesive governance in the storage and use of AI assets (feature data and models), everything is done in a bespoke manner, leading to compliance risks.
- Slow time-to-market of AI models, and a general inability to provide very fresh feature data or handle real-time data for ML models, which is critical for industries like finance, retail, or logistics where real-time insights can add significant business value. This point is all about the speed with which the data science team can develop their models and bring them to life in a production environment.
- Hard to derive a direct business value from the models, they exist in isolated environments that do not directly influence business operations. This then obviously makes it much harder to justify the investments required to develop and operationalize the models.
- Slow ramp-up time when onboarding new talent into the ML teams. Sharing available AI assets is complex because operational knowledge is held by a few individuals or groups.
We have summarized these reasons in the outer circle of the figure below. I am sure that there are other reasons that could potentially be more applicable to your specific environment - but these are the higher level ones that we see time and time again in our Hopsworks user discussions.
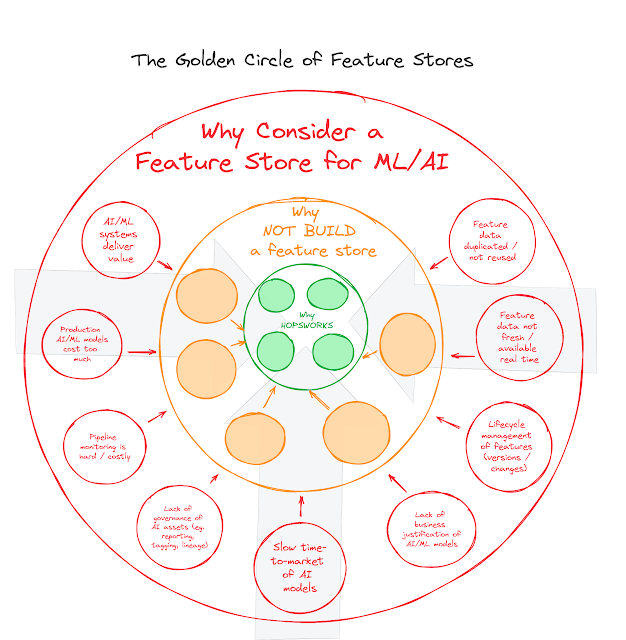
So now we know and understand why an organization requires a feature store - great! But that does not necessarily mean that they will actually go out to look for one in the marketplace! Many organizations, especially the “digital natives” that are tuned in to the latest technology trends (like ML/AI) nowadays have a tendency to at least consider building a software component themselves - instead of buying one. This is a good and worthwhile consideration, as it seems clear to me that there is a minimum of scale and maturity required before wanting to go “all-in” on this brand new technology. For many people, a homegrown solution might be “good enough”.
So how do we consider whether or not a roll-your-own solution is good enough or not? Let’s consider some criteria.
2. Why NOT BUILD, but BUY a Feature Store?
In the second layer of the diagram below, we consider some of the reasons / criteria that would warrant you to look at the BUY option instead of the BUILD option. Some of these reasons have also been covered in a
previous article, but let's revisit it here.
The most common reasons for buying and not building a feature store are:
- Maintenance Burden & Total Cost of Ownership (TCO): clearly, this is something that every mature IT organization will consider. Ultimately, this is related to the potential technical debt that this organization will want to incur, given the significant costs that could be associated with this down the line. It’s important to consider not just the short term, but also the longer term implications of a build vs. buy decision.
- Technical complexity: clearly, a piece of infrastructure software like a Feature Store, which will underpin all ML/AI applications that the organization would choose to develop, has a significant amount of technical complexity associated to it. It’s important to consider this, and to investigate the most crucial domains in which a “build” approach could encounter unexpected technical challenges.
- Offline / Online sync: one of the key characteristics of a feature store is that it will both contain the historical data of a feature dataset, as well as the most recent values. Both have their use and purpose, and need to be kept in sync inside the feature repository. Feature Stores like Hopsworks do this for you, but in a “build” scenario you would need to take this into account and do all the ETL data lifting yourself.
- Reporting and search: in any large machine learning system where you have dozens/hundreds/thousands of models in production, you would want and need the feature data to be findable, accessible, interoperable, and reusable - according to the so-called “F.A.I.R.” principles that we have described in this post. This seems easy - but if you consider all of the different combinations that you could have between versions of datasets, pipelines and models, it is clear that this is not a trivial engineering assignment.
- Metadata for versioning and lineage: similar to the previous point, a larger ML/AI platform that is hosting a larger number of models, will need metadata for its online and offline datasets, and will need to accurately keep track of the versions and lineage of the data. This will increasingly become a requirement, as governance for ML/AI systems will cease to be optional. Implementations of and compliance with the EU AI Act, will simply mandate this - and the complexity around implementing it at scale is significant.
- Time-travel and PITC joins: if we want to make the predictive results of our ML/AI systems explainable, we will need to be able to offer so-called “time travel” capabilities. This means that we can look at how a particular model yielded specific results based on the inputs that it received at a specific point in time. Feature Stores will need to offer this capability, on top of the requirement to guarantee that the models yield accurate and correct information at a given point in time - something we call “Point-in-time correctness”. Again, the technical complexity of implementing this yourself is not to be underestimated.
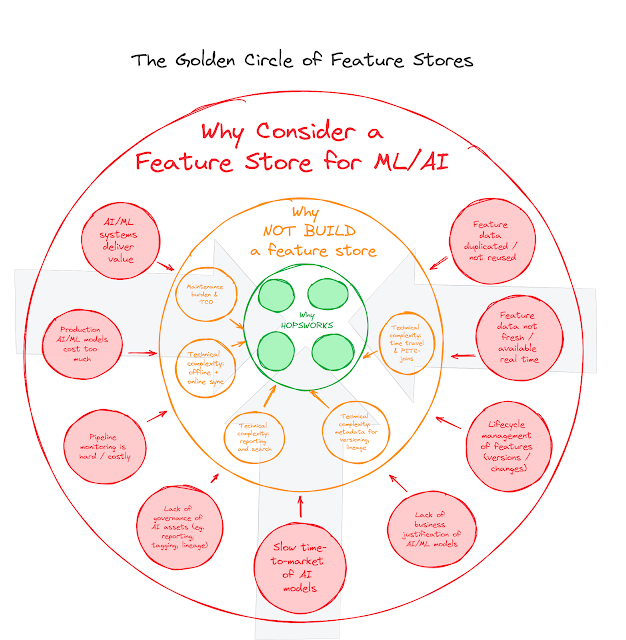
With that, we hope to have outlined some of the key reasons that you should consider buying, not building your feature store solution. At the end of the day this is a strategic decision that will be different for every organization - as long as the question is honestly asked and answered.
3. Why buy the Hopsworks Feature Store?
Last but not least, we would also like to offer the readers that have a) first decided that they need a feature store, and b) also decided that they will want to buy such a critical piece of infrastructure and not build it themselves, a perspective on why Hopsworks might be the best choice for your environment. In line with the previous “Golden Circle” visuals, we now get to the “inner” circle of the diagram:
Obviously we are conscious of the poor readability of the diagram, so here’s a cut-out that is a bit more readable:
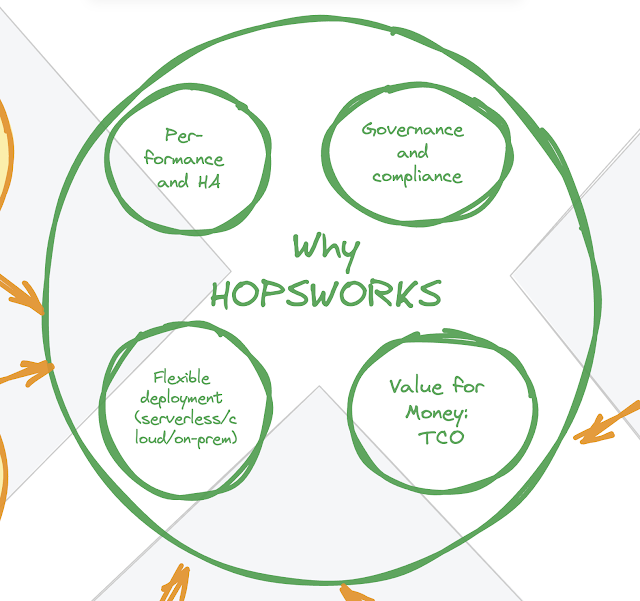
As you can see, we think that there are essentially 4 main reasons why the Hopsworks Feature Store solution could be the best possible fit for your environment. Let’s discuss each of these briefly:
- Performance and HA: Hopsworks has been working on the Feature Store for a number of years, with a top team of academic and industry specialists. We have integrated and embedded the best possible technologies, like for example RonBD, on the market, and have proven that this is currently giving us unparallelled performance. Take a look at these open benchmarks for yourself, and you will see that Hopsworks is in a league of its own with regards to performance. On top of that, we have been leveraging expertise in systems High-Availability to develop a feature store solution that can withstand the most demanding workloads.
- Flexible deployment (serverless / cloud / on-prem): Hopsworks is the only solution on the market that offers you the choice of deployment options that is best-suited for your specific environment. You can start small with a multi-tenant-based serverless environment, grow into a managed cloud deployment in your AWS / Azure / GCP account, or even repatriate the workload onto your own, on-premise hardware. No other solution offers this, today.
- Governance and compliance: Hopsworks has taken great pains at developing industry leading governance capabilities into the product. Versioning, lineage, time travel, search, security, monitoring and reporting - all of the advanced functionalities that a compliant solution will be required to deliver, now and in the future.
- Value for money, TCO: Hopsworks believes that in order for ML/AI to be successful, it needs to deliver value, and it needs to offer its users a clear Return on Investment. That means that the solution needs to be available at a reasonable price, and that consumption-based metrics cannot always be used for billing. We need to allow for testing, training, experimentation, learning and development - without requiring the customer to empty their pockets from day one, and all the while managing the total cost of ownership of the solution.
This brings us to the end of this article, where we have tried to discuss the “3 Whys” of Feature Store implementations. We hope this was a useful discussion, and are happy to discuss this with you as well. No doubt, we can make the argument even more detailed and refined, together.
All the best
Rik