On this blog, I have been writing about using graphs for Contact Tracing quite a bit. See
- the original blogpost series over here,
- the demo movies that I made
- the Neo4j Browser guide that you can use
Fortunately, these articles were very well received by the community - we have had a ton of discussions with a variety of different individuals, companies and governments about how to use this technology to prevent that the next lockdown would again require immobilising so many healthy people. If the pandemic's second wave hits, we all want people at risk / sick people to be separated from the healthy population, and manage the spread of the disease in this way. But all of that requires contact tracing to be effective and operational - which is not a trivial thing to do.
This is why I have been looking at creating a very easy to use testbed for Contact Tracing in Neo4j. I wanted to make it super easy for people to create synthetic contact tracing datasets, and then work with them to gain experience - valuable experience for the "real deal" when we have to manage that. That's what this post is about.
Installing "Faker" libraries for data generation in Neo4j
Quite some time ago, my friend Christoph of Graphaware, created some very cool tools for generating sample data. I even wrote about using these over here back in 2014. Christoph's tools used a library for generating dummy data, the so-called Faker libraries - you can still find these over here. Christoph's tool is no longer maintained it seemed, but other folks like Kees have picked up some of these ideas and have generated more modern versions of dummy data generation tools for Neo4j, and are actively maintaining it. This has taken the shape of neo4j-faker, a set of cypher functions and procedures that allow you to very quickly generate data - straight from within the Neo4j browser environment.
Using the plugin is really easy: you just need to download the latest .zip file from https://github.com/neo4j-contrib/neo4j-faker/releases, unzip it, and place the contents of the "dist" directory into the "plugins" directory of your neo4j server, and make the plugins part of your whitelisted functions/procedures in the neo4j.conf file. In my case that meant that I needed to add
dbms.security.procedures.unrestricted=apoc.*,gds.*,fkr.*
to the neo4j.conf file. Note that you can only have one of these whitelisting lines in your neo4j.conf file - if you have more than one you will find that not all of your procedures/functions will be accessible.
Creating a synthetic Contact Tracing graph with the Faker libraries
So let's start using this. The basic data model that I want to create is exactly the same as in the previous blogposts:

I have created a script for this on github of course: take a look at it over here. Some of the useful functions used include:
fkr.person('1940-01-01','2020-05-15'), to create a bunch of (:Person) nodes with birthdates between two dates.
fkr.stringElement("Sick,Healthy") to assign the healthstatus property in a random way, between these two "Sick" and "Healthy" values
fkr.stringElement("Grocery shop,Theater,Restaurant,School,Hospital,Mall,Bar,Park") to assign type properties to (:Place) nodes
When I run this script in the Neo4j browser, it only takes a few seconds to complete:

We can then verify that the data has been created correctly very simply.

It was much simpler and easier to implement using the Faker libraries than through the google sheets. The only troublesome part seems to - still - be the inferencing that we need to do to create the MEETS relationships - that step takes quite a bit of time, and we can probably simplify this even more.
Creating a synthetic meeting graph - without inferencing
The MEETS relationship is actually a very important one. It's calculated based on the inferred fact that if two people VISIT a Place at the same time, they are likely to have MET there.
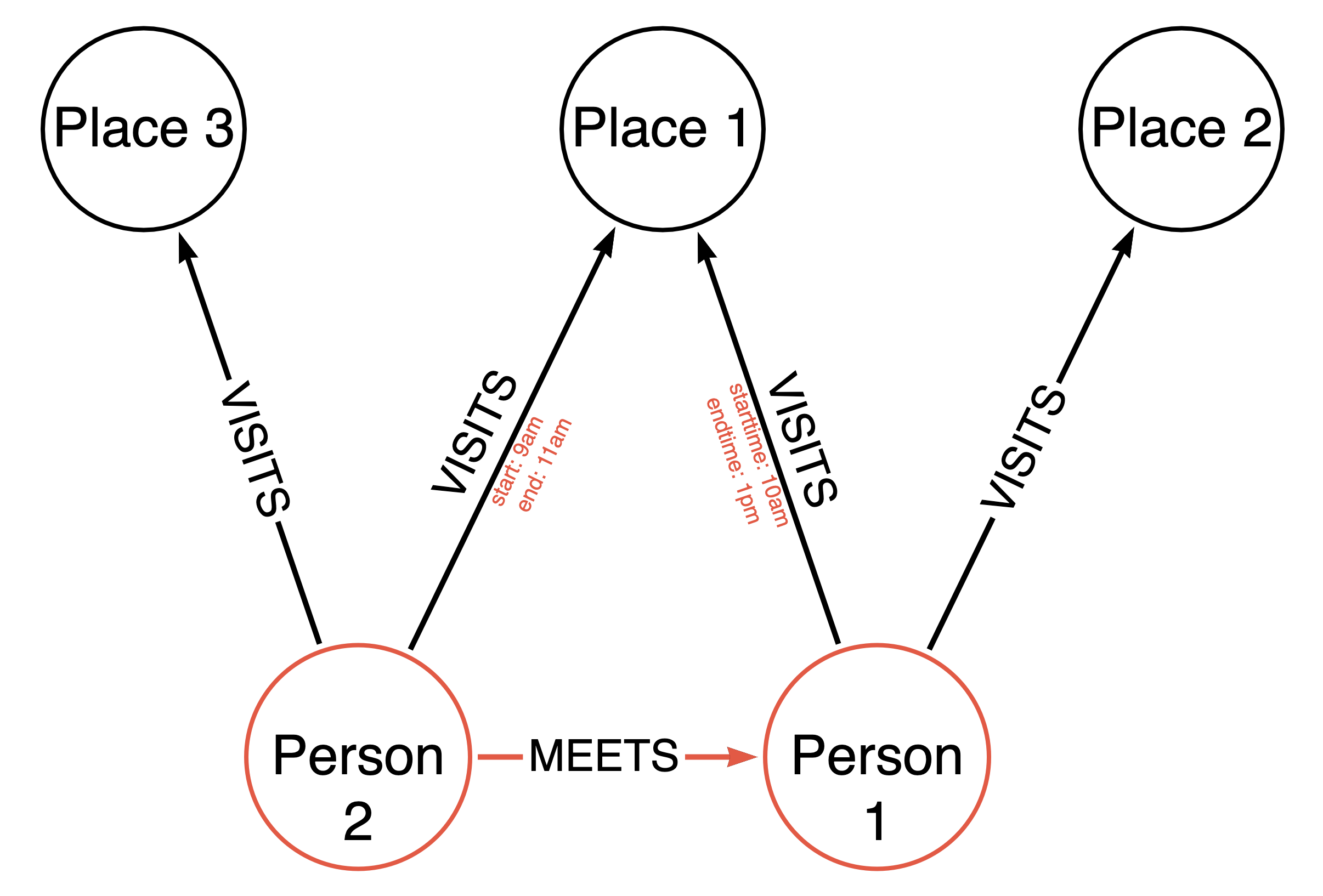
The reason this is important, is that most of the analytical graph data science algorithms require a so-called "mono partite" graph: they work best on relationships between nodes that have the same labels - in this case between Person-nodes. Calculating betweenness / pagerank or other algorithms wouldn't be nearly as accurate if we had to work with the Place nodes sitting between Person nodes. Therefore, it makes sense that we actually try to generate the MEETS relationships from the get-go in our synthetic graph.
The script for generating this graph in one go is actually even simpler than the one we reviewed earlier. You can find it over here on github. Generating the Person nodes is identical to what we did earlier, but generating the MEETS relationship is done with a procedure call that is part of the neo4j-faker plugin, ie fkr.createRelations. This procedure will take two sets of nodes (in this case, the selection of Person nodes that we create, on both the starting and the ending sides of the relationships), and creates relationships between these two sets based on
- the number of nodes that are in the starting set
- the cardinality that we specify between the starting and the ending set
Based on our assumptions we then run this relationship creation procedure 3 times, so that we get 3 times as many MEETS relationships as we have Person nodes. Running these two queries returns under a second:

This then allows us to proceed with all of our graph analytics queries that we wrote about in the previous blogposts.
I hope you think this is an interesting way of generating the Contact Tracing testbed - I certainly think it allows for a very quick set of iterations and tests that could prove to be very useful when we actually start analysing the datasets for real.
As always, I would really welcome your feedback.
All the best
Rik
No comments:
Post a Comment