
Today, we'll continue that journey, and talk about Lucene, transaction support, and SOLR. Should be fun!
2. Does Neo4j use Lucene
This one is a lot simpler to answer - luckily - than the scale question that we tackled in the previous post. The answer is: YES, Neo4j does indeed leverage the (full-text) indexing capabilities of Lucene to create "graph indexes" on specific node-label-property combinations.
Graph Indexes are a little different from what you may be used to in the traditional database world, as they are fundamentally used in a different way. In a native graph database like Neo4j, you basically only use indexes
- to find a starting point in your traversal
- gather heuristics about the different ways that you can do the traversal, in other ways, enable the query planner to do its job efficiently
All of these indexes are based on Lucene, but you do have two ways to use it.
- you can manually add node- or relationship-properties to an Index, a system we call "Manual Indexes" (some people mistakenly call them "legacy" indexes - but sobeit) which is described in detail over here. This is the older way of using Neo4j indexes, and basically allows for very fine grained, but manual (you have to do it yourself and add stuff to an index from your code) way of indexing graph content. The database does not guarantee that the index is consistent with the database - you may have data in the database that is not indexed (because you did not manually add it to the index), and you could also have data in the index that is no longer physically in the database (because you forgot to remove it from the index, for example).
- you can use Neo4j's fully automated "schema indexes" - which do guarantee consistency between the index and the database, as you would expect from a database. Under the hood these also use Lucene, but they automate the adding/updating/deletion of data from the index when you do a corresponding operation on the graph. This essentially provides the database with more information about the data that it is storing, and will enable us to do much more intelligent management and querying of the data as a consequence. You can read up on Schema Indexing over here.
- Max De Marzi's great blog about it
- Stefan Armbruster's work on the topic
- the eternal blog by Michael Hunger
- a developer guide to fulltext search in Neo4j
3. Does Neo4j support Transactions
Another fairly easy one to answer, but maybe a bit more tricky to explain.
In short: YES! Neo4j is a fully transactional, ACID, "you-can-trust-me-as-the-source-of-truth" database. It does not loose your data - full stop. There's quite a bit of material written up on that, which I won't regurgitate here. Take a look at
- the developer manual, including the description about the transactional endpoint
- a very nice, more high-level article on the topic of what it means to be a transactional database, or not.
In many ways, I find this autocomplete question a bit perplexing and bizarre. It's kind of weird that, in today's world of NOSQL databases, it has become kind of the default for database management systems (ie, things that are supposed to manage and safeguard your precious data) to loose or corrupt data. It's bon ton for these systems to give up transaction support - one of the fundamental underpinnings of a safe data management system - and therefore assume that "we may loose some tiny bits of data here or there, but that's ok". Don't get me wrong - I totally get NOSQL, and I actually respect it greatly in many ways - but I do feel that this ACID transactional stuff should not be discarded lightly. If you are going to assume that you are going to be loosing data - then you better damn well know what you're doing and what kind of data it is that you may be loosing. The consequences may be bigger than you think.
On that topic, I also JUST HAVE TO post this video that I saw a few years ago from James Mickens (then at Microsoft research, now at Harvard) at Monitorama PDX 2014:
Watch the entire video for lots of fun, but from minute 12m30s or so James really rants about the lack of transactional support in NOSQL databases - it's hugely funny and quite accurate in my book: let your reads and writes choose their own destiny!
The point being: transaction support is still ever so important in modern day applications, and it should be. Especially in the connected domains stored in graph databases, transaction support should be considered crucially important. The reason for this is quite clear and simple: in a graph, data corruption not only affects the entity that is being written to, but could potentially affect the entire connected structure that is connected to that entity. If I get a node/relationship write operation wrong, I may end up disconnecting / wrongly connecting entire parts of the graph structure - and therefore we have a much more troubling data consistency requirement than most other databases may have. Graph databases really should never be allowed to loose or corrupt data - it's just too important.
So: recapping the "does neo4j support transactions" question: yes it does, and that's a very, very good thing.
4. Does Neo4j use Solr
The fourth autocomplete question that we are going to answer, is kind of an easy one - mostly because it is related to the Lucene question above.
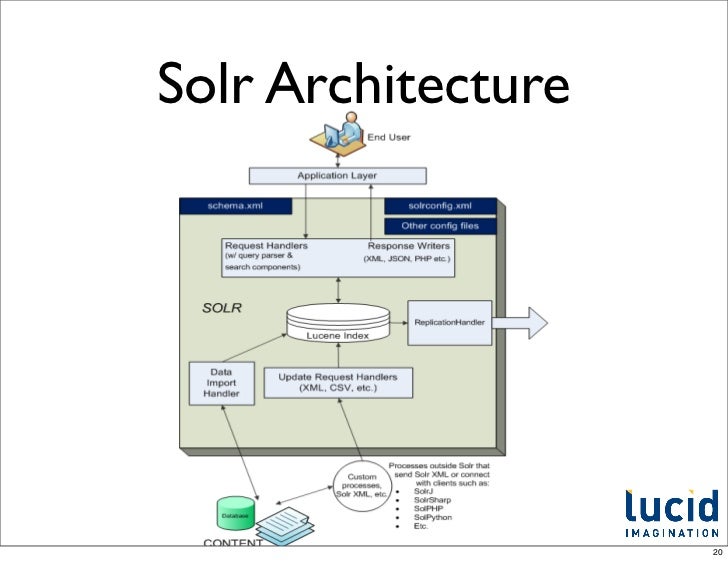
- this first picture kind of shows you that SOLR essentially uses Lucene indexes as it's core data infrastructure.
- it also just simply says so on the SOLR homepage: SOLR is built on Apache Lucene.
- last but not least: there seems to be a bit of a discussion / "frenemy" relationship between SOLR and ElasticSearch - as both are essentially based on the same core Lucene infrastructure. I am no expert on any of this by a long shot - but it seems relevant to mention this.

 So we can really summarize the answer to this Neo4j Autocomplete question with another Google search: does solr use lucene? Yes it does.
So we can really summarize the answer to this Neo4j Autocomplete question with another Google search: does solr use lucene? Yes it does.
From an end-user's point of view, the importance is of course in what the Lucene integration brings to Neo4j in terms of full-text graph search and graph querying. This is really important and useful in many ways. However, the Neo4j Engineering team is also hard on some added (composite) indexing functionality that may change and enrich the indexing infrastructure in Neo4j.
So that's that - answered another couple of high-flying questions that were clearly top-of-mind for some of you. I hope it was useful.
Let me know if you have any comments.
Rik
Note added after publication:
No comments:
Post a Comment